
FPGA Implementation of TFT 1.8 inch SPI 128×160 Display ROM Interface
Simple Description:
This ST7735R is a display controller used in small TFT (Thin-Film Transistor) LCD displays. It is often used in combination with microcontrollers or FPGAs to drive these displays. The controller supports the Serial Peripheral Interface mode of communication for sending commands and data to the display. This TFT display helps with a greater number of image and video processing applications. Here we have implemented this TFT display in FPGA hardware implementation using Verilog HDL with a novelty-based architecture design. Finally shown the output with TFT Display.
List of the following materials will be included with the Downloaded Backup: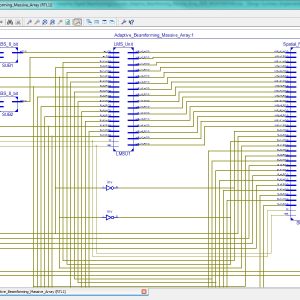
FPGA Implementation of the Adaptive Digital Beamforming for Massive Array
Base Paper Abstract:
With the rise of 5G networks and the increasing number of communication devices, improving communication quality is essential. One approach is adaptive digital beamforming, which adjusts an antenna array’s radiation pattern based on the desired received signal. Adaptation based on Least-Mean Squared (LMS) and its variants is still one of the most common literature methods. Although LMS techniques present good computational performance, the increase in antennas’ numbers led to high-performance hardware. Platforms such as Field Programmable Gate Arrays (FPGAs), designed for massive array systems, enables high-performance energy-efficient architectures. This work proposes a parallel implementation of a massive array beamforming composed of a spatial filter and adaptation unit based on LMS on FPGA. The proposed design presents ten times fewer hardware requirements and 30 times less power consumption than state of the art.
List of the following materials will be included with the Downloaded Backup:
FPGA IP Core for DC Motor Control with Adaptive Neural Network PID Tuning
Base paper Abstract:
Traditional proportional integral derivative (PID) falls short for precise control of DC motor speed under changing conditions. This paper presents a novel FPGA based IP (intellectual property) core for real-time PID parameter adjustment utilizing a multilayer neural network and the back propagation neural network algorithm. The design is implemented entirely in verilog HDL (hardware description language) using the Vivado 2023.1 tool in the Zynq 7z020 SoC (system on chip), with highly efficient resource utilization of 7.37% look-up table (LUT), 1.92% flip-flops, and 3.57% memory. The co-simulation results show a fast rise time of 0.00496s, a settling time of 0.0083s, a lower integral absolute error (IAE) of 0.045, and a minimum overshoot of 0.45%, validating the effectiveness of the proposed controller for comprehensive motion control systems. This dynamic approach outperforms traditional PID controllers by adapting to changing conditions, significantly improving rise time and settling time, which are critical factors in healthcare applications. Other key features of this work include precise duty cycle generation at a 10 kHz switching frequency for accurate motor speed control and an incremental encoder interface for high-resolution position feedback.
List of the following materials will be included with the Downloaded Backup: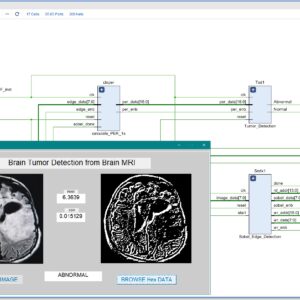
FPGA-Based Brain Tumor Detection from MRI Using 3×3 Convolution Soft IP Core with Stride 1
Base Paper Abstract:
This paper presents an efficient FPGA-based system for automatic brain tumor detection from MRI images using a 3x3 convolutional edge detection method with stride 1. The proposed architecture is developed as a soft IP core in Verilog HDL and synthesized on a Xilinx Zynq 7000 FPGA platform. The system applies a customized 3x3 convolution kernel over each MRI image with stride 1, ensuring that every pixel is processed and fine image details are preserved for accurate tumor detection. Edge detection results are used to segment and highlight abnormal regions, and a thresholding mechanism is employed to differentiate between normal and abnormal images. Hardware resource utilization—including look-up tables (LUTs), flip-flops (FFs), and power consumption—is analyzed after synthesis to verify system efficiency. Experimental results confirm that the proposed FPGA implementation provides real-time processing and reliable brain tumor detection with low power usage, making it suitable for portable and embedded medical devices. The stride 1 approach guarantees maximum detection accuracy and detailed edge representation in all test cases.
List of the following materials will be included with the Downloaded Backup: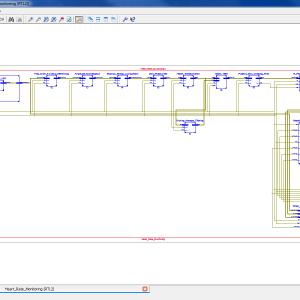
FPGA-Based System For Heart Rate Monitoring
Abstract:
The continuous monitoring of cardiac patients requires an ambulatory system that can automatically detect heart diseases. This study presents a new field programmable gate array (FPGA)-based hardware implementation of the QRS complex detection. The proposed detection system is mainly based on the Pan and Tompkins algorithm, but applying a new, simple, and efficient technique in the detection stage. The new method is based on the centred derivative and the intermediate value theorem, to locate the QRS peaks. The proposed architecture has been implemented on FPGA using the Xilinx System Generator for digital signal processor and the Nexys-4 FPGA evaluation kit. To evaluate the effectiveness of the proposed system, a comparative study has been performed between the resulting performances and those obtained with existing QRS detection systems, in terms of reliability, execution time, and FPGA resources estimation. The proposed architecture has been validated using the 48 half-hours of records obtained from the Massachusetts Institute of Technology - Beth Israel Hospital (MITBIH) arrhythmia database. It has also been validated in real time via the analogue discovery device.
List of the following materials will be included with the Downloaded Backup:
Frequency-Boost Jitter Reduction for Voltage-Controlled Ring Oscillators
Ring oscillators (ROs) are popular due to their small area, modest power, wide tuning range, and ease of scaling with process technology. However, their use in many applications is limited due to poor phase noise and jitter performance. Thermal noise and flicker noise contribute jitter that decreases inversely with oscillation frequency. This paper describes a frequency boost technique to reduce jitter in ROs. We boost the internal oscillation frequency and introduce a frequency divider following the oscillator to maintain the desired output frequency. This approach offers reduced jitter as well as the opportunity to trade off output jitter with power for dynamic performance management. The oscillator has 32 operating modes, corresponding to different values for the ring size and frequency division. In a 0.5-µm CMOS process, the highest oscillation frequency achieved is 25 MHz with a root-mean-square period jitter of 54 ps and a power consumption of 817 µW at 5 V supply. A jitter model for current-starved oscillators was derived and verified by measurement; a direct relationship between oscillation frequency and jitter was derived and measured. Compared with other oscillators, this design achieves the highest performance in terms of jitter per unit interval and figure-of-merit. The performance is expected to improve in more advanced technologies. The results are summarized to offer design guidance based on the frequency boost technique. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Full Swing Local Bitline SRAM Architecture Based on the 22 nm FinFET Technology for Low Voltage Operation
The previously proposed average-8T static random access memory (SRAM) has a competitive area and does not require a write-back scheme. In the case of an average-8T SRAM architecture, a full-swing local bitline (BL) that is connected to the gate of the read buffer can be achieved with a boosted wordline (WL) voltage. However, in the case of an average-8T SRAM based on an advanced technology, such as a 22-nm FinFET technology, where the variation in threshold voltage is large, the boosted WL voltage cannot be used, because it degrades the read stability of the SRAM. Thus, a full-swing local BL cannot be achieved, and the gate of the read buffer cannot be driven by the full supply voltage (VDD), resulting in a considerably large read delay. To overcome the above disadvantage, in this paper, a differential SRAM architecture with a full-swing local BL is proposed. In the proposed SRAM architecture, full swing of the local BL is ensured by the use of cross-coupled pMOSs, and the gate of the read buffer is driven by a full VDD, without the need for the boosted WL voltage. Various configurations of the proposed SRAM architecture, which stores multiple bits, are analyzed in terms of the minimum operating voltage and area per bit. The proposed SRAM that stores four bits in one block can achieve a minimum voltage of 0.42 V and a read delay that is 62.6 times lesser than that of the average-8T SRAM based on the 22-nm FinFET technology. The proposed architecture of this paper is analysis the area and power consumption using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Full-Array Boolean Logic CIM Macro with Self-Recycling 10T-SRAM Cell for AES Systems
Base Paper Abstract:
Computing in memory (CIM), which alleviates the need to transfer a large amount of data between processor and memory, significantly reducing latency and energy consumption, is a promising new computing architecture for addressing the von Neumann bottleneck problem. This article proposes a CIM array structure composed of self-recycling 10T static random access memory (SRAM) cells, which can realize orthogonal data writing, and multiple Boolean logical operations for the entire array. The self-recycling and full-array activation characteristics are extremely suitable for accelerating diverse data processing algorithms such as the Advanced Encryption Standard (AES). A 4-kb SRAM is implemented in 55-nm CMOS technology to verify the effectiveness of the design. Compared with other state-of-threat architectures, the throughput and the operating frequency of the proposed CIM macro are increased to 843 GOPS/kb (2.64×) and 823.7 MHz (2.6×), respectively. The energy efficiency reaches 246.9 TOPS/W. When applied to the AES, the energy consumption is 35.77% less than the digital CIM architecture that is not self-recycling.
List of the following materials will be included with the Downloaded Backup:
Fully Pipelined Low-Cost and High-Quality Color Demosaicking VLSI Design for Real-Time Video Applications
This system presents a fully pipelined color demosaicking design. To improve the quality of reconstructed images, a linear deviation compensation scheme was created to increase the correlation between the interpolated and neighboring pixels. Furthermore, immediately interpolated green color pixels are first to be used in hardware-oriented color demosaicking algorithms, which efficiently promoted the quality of the reconstructed image. A boundary detector and boundary mirror machine were added to improve the quality of pixels located in boundaries. In addition, a hardware sharing technique was used to reduce the hardware costs of three interpolators. Finally these are implemented and get the simulated result is compared to the previous architecture. The code are simulated and power, area, cost are taken using Xilinx 14.2 software and MATLAB. Compared with the previous low complexity designs, this work has the benefits in terms of low cost, low power consumption, and high performance.
List of the following materials will be included with the Downloaded Backup:
Fully Reused VLSI Architecture of FM0Manchester Encoding Using SOLS Technique for DSRC Applications
The dedicated short-range communication (DSRC) is an emerging technique to push the intelligent transportation system into our daily life. The DSRC standards generally adopt FM0 and Manchester codes to reach dc-balance, enhancing the signal reliability. Nevertheless, the coding-diversity between the FM0 and Manchester codes seriously limits the potential to design a fully reused VLSI architecture for both. In this paper, the similarity-oriented logic simplification (SOLS) technique is proposed to overcome this limitation. The encoding capability of this paper can fully support the DSRC standards of America, Europe, and Japan. This paper not only develops a fully reused VLSI architecture, but also exhibits an efficient performance compared with the existing works. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
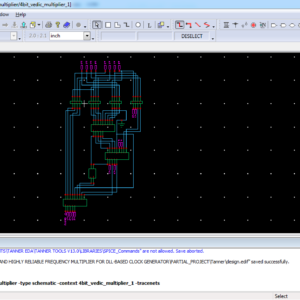
Gate diffusion input based 4-bit Vedic multiplier design
Abstract:
A multiplier is one of the key hardware blocks in most of the processors. Multiplication is a lengthy, time-consuming task. Vedic multiplication in field programmable gate array implementation has been proven effective in reducing the number of steps and circuit delay. Conventionally at the circuit level, complementary metal oxide semiconductor (CMOS) logic is used to design a multiplier. In CMOS circuits, the area is always an issue. Gate diffusion input (GDI)-based logic has been explored in the literature to reduce the number of transistors for various logic functions. Thus, Vedic mathematics, on the one hand, simplifies the multiplication process and reduces the delay; while on the other hand, GDI technique helps in minimizing the transistor count (TC) and reduction in power. Therefore, this study puts forth a GDI logic-based 4-bit Vedic multiplier. To study the effectiveness of the GDI logic, the transient response of a 2-bit Vedic multiplier using CMOS and GDI is compared. For the 4-bit Vedic multiplier, two design approaches are taken into consideration. The performance of these circuits is analyzed in terms of average power dissipation, delay, and TC. The effect of supply voltage scaling is also studied. The circuit simulations are carried out at 130 nm for bulk metal oxide semiconductor field effect transistor predictive technology model-based device parameters.
List of the following materials will be included with the Downloaded Backup:
Glitch Energy Reduction and SFDR Enhancement Techniques for Low Power Binary Weighted Current Steering DAC
This brief proposes a glitch reduction approach by dynamic capacitance compensation of binary-weighted current switches in a current-steering digital-to-analog converter (DAC). The method was proved successfully by a 10-bit 400-MHz pure binary-weighted current steering DAC with a minimum number of retiming latches. The experiment results yield very low-glitch energy during major carry transitions at output.
List of the following materials will be included with the Downloaded Backup:
Hamming based Single Fault Error Correction Code
Proposed Abstract:
Signal processing and communication systems often use digital filters. In certain circumstances, the dependability of such systems is essential, prompting the construction of fault-tolerant filters. Many methods that take use of the structure and characteristics of the filters to achieve fault tolerance have been put forward throughout the years. Technology advances permit more intricate systems with several filters. It is typical for some of the filters in such complicated systems to function in simultaneously, for instance by using the same filter on several input signals. Recently, a straightforward method for achieving fault tolerance was given that takes use of the existence of parallel filters. This paper expands on that concept to demonstrate how error correction codes (ECCs), in which each filter is the equivalent of a bit in a conventional ECC, may be used to secure parallel filters. When there are several parallel filters operating simultaneously, this new technique enables more effective protection. The efficiency of the method in terms of protection and implementation cost is assessed using a case study of parallel finite impulse response filters.
List of the following materials will be included with the Downloaded Backup:
Hardware Architecture for Adaptive Edge Directed Interpolation Algorithm
Base Paper Abstract:
Demosaicking refers to the reconstruction of full color image by the incomplete color samples produced by the single-chip image sensor. So there is a need of interpolation to obtain the missing color pixels. In this work a hardware architecture has been proposed for the adaptive edge-directed interpolation algorithm which uses an edge estimator for the interpolation. The proposed hardware architecture is implemented in Verilog HDL (Hardware Description Language) and synthesized using Cadence Genus compiler with 90nm technology in typical mode. For the proposed architecture, the power dissipation is found to be 26 mW, delay is 7.2 ns and requires 2.3 mm2 area. The demosaicked images obtained using the proposed architecture is observed to have better image quality in terms of peak signal-to-noise ratio and structural similarity while comparing with existing architectures.
List of the following materials will be included with the Downloaded Backup:
Hardware Efficient Architecture for Multiple Quantized Gaussian Noise Generation
This paper presents two novel architectures to generate a number of quantized Gaussian noises. The first architecture exploits inversion through uniform segmentation, enabling a uniform look up table (LUT) splitting technique to efficiently generate quantized Gaussian noise while maintaining reasonable tail quality in Gaussian noise generation. The second architecture utilizes inversion through hierarchical segmentation and a probability-based LUT selection, significantly reducing the total LUT size while preserving the tail quality of the generated Gaussian noise. Both designs generate multiple uniform random numbers by cascading combinational circuits, which improves Gaussian noise generation efficiency compared to the conventional linear feedback shift register-based method. Compared to the previous architecture based on inversion through hierarchical segmentation, the proposed uniform segmentation architecture achieves a 6.02x improvement, when implemented on a field-programmable gate array device, in terms of throughput per configurable logic block, and the proposed hierarchical segmentation architecture achieves a 2.71x improvement.
List of the following materials will be included with the Downloaded Backup: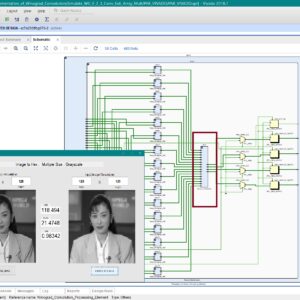
Hardware Implementation of Improved Banker’s Fixed-Point Rounding Algorithm
Base Paper Abstract:
In recent years, FPGA-based convolutional neural networks (CNNs) accelerator has received tremendous research interest, especially in fields such as autonomous driving and robotics. For the purpose of accelerating convolution computations, Winograd fast convolution algorithm is frequently employed. However, during implementation of the Winograd algorithm on FPGA, multiple rounding operations occur, and the accuracy of these operations substantially impacts the convolution results. The banker’s rounding algorithm, compared to other rounding algorithms, has advantages such as a more symmetric error distribution and smaller errors, making it suitable for Winograd convolution computation. However, the conventional banker’s rounding algorithm is proposed for floating-point calculations, yet FPGA implements fixed-point arithmetic. Moreover, it frequently rounds 0.5 to 0, leading to the issue of convolution weight invalidation and introducing significant errors. To overcome these challenges, an improved hardware circuit designed for implementing the fixed-point banker’s rounding algorithm is proposed. Experimental results show that compared with common rounding up and rounding down methods, the proposed algorithm exhibits smaller errors and effectively resolves the issue of weight invalidation in conventional banker’s rounding, leading to a significant 55.6% improvement in computational accuracy.
List of the following materials will be included with the Downloaded Backup:
Hardware-Efficient Logarithmic Floating-Point Multipliers for Error-Tolerant Applications
Base Paper Abstract:
The increasing computational intensity of important new applications poses a challenge for their use in resource restricted devices. Approximate computing using power-efficient arithmetic circuits is one of the emerging strategies to reach this objective. In this article, five hardware-efficient logarithmic floating-point (FP) multipliers are proposed, which all use simple operators, such as adders and multiplexers, to replace complex and costlier conventional FP multipliers. Radix-4 logarithms are used to further reduce the hardware complexity. These designs produce double-sided error distributions to mitigate error accumulation in complex computations. The proposed multipliers provide superior trade-offs between accuracy and hardware, with up to 30.8% higher accuracy than a recent logarithmic FP design or up to 68× less energy than the conventional FP multiplier. Using the proposed FP logarithmic multipliers in JPEG image compression achieves higher image quality than a recent logarithmic multiplier design with up to 4.7 dB larger peak signal-to-noise ratio. For training in benchmark NN applications, the proposed FP multipliers can slightly improve the classification accuracy while achieving 4.2× less energy and 2.2× smaller area than the state-of-the-art design.
List of the following materials will be included with the Downloaded Backup: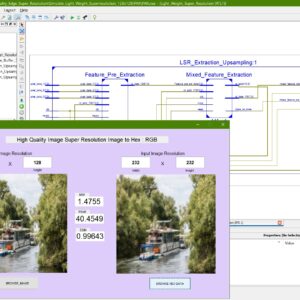
Hardware-Optimized High-Quality Super-Resolution Accelerator for Real-Time Edge Computing
Base Paper Abstract:
Super-resolution (SR) techniques have been employed to construct high-definition images from low-quality images. Various neural networks have demonstrated excellent image-reconstruction quality in SR accelerators. However, deploying SR networks on edge devices is limited by resources and power consumption induced by significant algorithm parameters, computation complexity, and external memory accesses. This work explores the hardware algorithm co-design techniques to provide an end-to-end platform with a lightweight super-resolution network (LSR) and an efficient, high-quality SR accelerator HDSuper. For algorithm design, the improved depth-wise separable convolution and pixel shuffle layers are developed to reduce network size and computation complexity by considering the hardware constraints. Also, the improved channel attention (CA) blocks enhance the image reconstruction quality. For hardware accelerator design, we design a unified computing core (UCC) combined with an efficient flattening-and allocation (F-A) mapping strategy to support various operators with high computational utilization. In addition, we design the patch computing scheme to reduce the external memory access of the hardware architecture. Based on the evaluation, the proposed algorithm achieves high-quality image reconstruction with 37.44d B PSNR. Finally, the FPGA demonstration and ASIC layout under UMC 55nm are achieved with low power consumption (2.08 W and 152mW) under the lowest hardware resources compared to the state-of-the-art works.
List of the following materials will be included with the Downloaded Backup:
HDL-Based Modeling Approach for Digital Simulation of Adiabatic Quantum Flux Parametron Logic
Abstract:
AQFP (adiabatic quantum-flux-parametron) circuits are currently verified by analog-based simulation, which would be an obstacle for large-scale circuits design. In this paper, we present a logic simulation model for AQFP logic. We made a functional model based on a finite-state machine approach using a hardware description language (HDL), which enables the simulation of large-scale AQFP circuits using commercially available logic simulation tools. We have developed a library for logic simulation and implemented an 8-bit carry look-ahead adder, which is composed of over 1000 Josephson junctions (JJs). We also include timing information in our logic simulation models for timing analysis. Since the library is based on a parameterized approach, it can be easily modified for different fabrication technologies and low-level circuit parameters.
List of the following materials will be included with the Downloaded Backup:
High Performance Accurate and Approximate Multipliers for FPGA based Hardware Accelerators
Abstract:
Multiplication is one of the widely used arithmetic operations in a variety of applications, such as image/video processing and machine learning. FPGA vendors provide high performance multipliers in the form of DSP blocks. These multipliers are not only limited in number and have fixed locations on FPGAs but can also create additional routing delays and may prove inefficient for smaller bit-width multiplications. Therefore, FPGA vendors additionally provide optimized soft IP cores for multiplication. However, in this work, we advocate that these soft multiplier IP cores for FPGAs still need better designs to provide high-performance and resource efficiency. Towards this, we present generic area-optimized, low-latency accurate and approximate soft-core multiplier architectures, which exploit the underlying architectural features of FPGAs, i.e., look-up table (LUT) structures and fast carry chains to reduce the overall critical path delay and resource utilization of multipliers. Compared to Xilinx multiplier LogiCORE IP, our proposed unsigned and signed accurate architecture provides up to 25% and 53% reduction in LUT utilization, respectively, for different sizes of multipliers. Moreover, with our unsigned approximate multiplier architectures, a reduction of up to 51% in the critical path delay can be achieved with an insignificant loss in output accuracy when compared with the LogiCORE IP. For illustration, we have deployed the proposed multiplier architecture in accelerators used in image and video applications, and evaluated them for area and performance gains.
List of the following materials will be included with the Downloaded Backup:
High Performance FIR and IIR Filters Based on FPGA for 16 Hz Signal Processing
Base Paper Abstract:
The goal of the research to design and implement digital filters (Finite Impulse Response (FIR) and Infinite Impulse Response (IIR)) based on Field Programmable Gate Array (FPGA) by using the copulation between MATLAB/Simulink and Xilinx ISE Design Suite programs. low pass digital filter was implemented with different types of windowing methods that calculate the filter coefficient of FIR filter and different types of IIR filter with three numbers of filter order that are (5th order, 8th order, and 10th order). These different types of digital filters and filter orders are applied with the addition of a sine signal with a frequency of 16 Hz and a random noise signal. The work was done by two approaches: the first by simulation method through coupling between MATLAB/Simulink and Xilinx ISE Design Suite programs. While the second is by the practical method of loading these simulation block diagrams on FPGA. The performance of the work is measured by the difference between the sine signal and filtered signal and by the difference between the simulation results and practical results. Using FPGA with digital filters in this research gives a major advantage which is the simulation results equal to the practical results (Difference equal to zero).
List of the following materials will be included with the Downloaded Backup:
High Performance VLSI architecture for M-PSK modems
Abstract:
M-PSK (phase shift keying) modulation schemes are used in many high-speed applications like satellite communication, as they are more bandwidth and power efficient compared with other schemes. This study presents very large scale integrated circuits (VLSI) architectures for modulators and demodulators of quadrature phase shift keying (QPSK), 4PSK, 8PSK and 16PSK systems, based on the principle of direct digital synthesis. The proposed modulators do not use any multiplier in contrast to the conventional modulators and hence they are relatively fast and area efficient. Based on the coherent detection technique, this study proposes new demodulation algorithms for 4PSK, 8PSK and 16PSK systems which can be implemented both in analogue and digital domains. This study also presents VLSI architectures for all the proposed algorithms. The proposed architectures are described in VHDL and implemented on Xilinx field programmable gate arrays (FPGAs). The simulation results verify their functional validity and implementation results show the suitability of the proposed architectures for satellite communications.
List of the following materials will be included with the Downloaded Backup:
High Speed and Energy Efficient Carry Skip Adder Operating Under a Wide Range of Supply Voltage Levels
Abstract:
In this paper, we present a carry skip adder (CSKA) structure that has a higher speed yet lower energy consumption compared with the conventional one. The speed enhancement is achieved by applying concatenation and incrimination schemes to improve the efficiency of the conventional CSKA (Conv-CSKA) structure. In addition, instead of utilizing multiplexer logic, the proposed structure makes use of NAND-NOR-Invert (NNI) and NOR-NAND-Invert (NNI) compound gates for the skip logic. The structure may be realized with both fixed stage size and variable stage size styles, wherein the latter further improves the speed and energy parameters of the adder. Finally, a hybrid variable latency extension of the proposed structure, which lowers the power consumption without considerably impacting the speed, is presented. This extension utilizes a modified parallel structure for increasing the slack time, and hence, enabling further voltage reduction. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
High speed and low power preset-able modified TSPC D flip-flop design and performance comparison with TSPC D flip-flop
Abstract:
Positron emission tomography (PET) is a nuclear functional imaging technique that produces a three-dimensional image of functional organs in the body. PET requires high resolution, fast and low power multichannel analog to digital converter (ADC). A typical multichannel ADC for PET scanner architecture consists of several blocks. Most of the blocks can be designed by using fast, low power D flip-flops. A preset-able true single phase clocked (TSPC) D flip-flop shows numerous glitches (noise) at the output due to unnecessary toggling at the intermediate nodes. Preset-able modified TSPC (MTSPC) D flip flop have been proposed as an alternative solution to alleviate this problem. However, the MTSPC D flip-flop requires one extra PMOS to suspend toggling of the intermediate nodes. In this work, we designed a 7-bit preset-able gray code counter by using the proposed D flip-flop. This work involves UMC 180 nm CMOS technology for preset-able 7-bit gray code counter where we achieved 1 GHz maximum operation frequency with most significant bit (MSB) delay 0.96 ns, power consumption 244.2 μW (micro watt) and power delay product (PDP) 0.23 pJ (Pico joule) from 1.8 V power supply.
List of the following materials will be included with the Downloaded Backup:
High Speed Area Efficient VLSI Architecture of Three Operand Binary Adder
Abstract:
Three-operand binary adder is the basic functional unit to perform the modular arithmetic in various cryptography and pseudorandom bit generator (PRBG) algorithms. Carry save adder (CS3A) is the widely used technique to perform the three-operand addition. However, the ripple-carry stage in the CS3A leads to a high propagation delay of O(n). Moreover, a parallel prefix two-operand adder such as Han-Carlson (HCA) can also be used for three-operand addition that significantly reduces the critical path delay at the cost of additional hardware. Hence, a new high-speed and area-efficient adder architecture is proposed using pre-compute bitwise addition followed by carry prefix computation logic to perform the three-operand binary addition that consumes substantially less area, low power and drastically reduces the adder delay to O(log2 n). The proposed architecture is implemented on the FPGA device for functional validation and also synthesized with the commercially available 32nm CMOS technology library. The post-synthesis results of the proposed adder reported 3.12, 5.31 and 9.28 times faster than the CS3A for 32-, 64- and 128- bit architecture respectively. Moreover, it has a lesser area, lower power dissipation and smaller delay than the HC3A adder. Also, the proposed adder achieves the lowest ADP and PDP than the existing three-operand adder techniques.
List of the following materials will be included with the Downloaded Backup:
High Speed Low Power and Highly Reliable Frequency Multiplier for DLL Based Clock Generator
To propose a novel frequency multiplier with high-speed, low-power, and highly reliable design for a delay-locked loop-based clock generator to generate a multiplied clock with a high frequency and wide frequency range. The proposed edge combiner achieves a high-speed and highly reliable operation using a hierarchical structure and an overlap canceller. In addition, by applying the logical effort to the pulse generator and multiplication-ratio control logic design, the proposed frequency multiplier minimizes the delay difference between positive- and negative-edge generation paths, which causes a deterministic jitter. Finally, a numerical analysis is performed to analyze and compare the performance of the proposed frequency multiplier with that of previous frequency multipliers. The proposed frequency multiplier is fabricated using a 0.13-µm CMOS process technology, and has the multiplication ratios of 1, 2, 4, 8, and 16, and an output range of 50 MHz–3.3 GHz. The frequency multiplier achieves power consumption is 17.49mW. The proposed architecture of this paper is analysis the logic size, area and power consumption using tanner tool.
List of the following materials will be included with the Downloaded Backup:
High-performance CORDIC-based approximate MAC architectures for FPGA platforms
CORDIC is a versatile algorithm frequently used in different signal-processing operations. While using CORDIC based computations in evaluating trigonometric and transcendental functions is quite prevalent, the resource overhead associated with its implementation does not justify its use in evaluating linear functions like multiplication and addition. However, with the emergence of approximate computing as an attractive paradigm for error-resilient applications, the algorithm can be used to design approximate linear computational units that completely justify the accuracy-performance trade-offs. In this paper, we model the CORDIC-based computations to emulate the multiply-accumulate operation, albeit with some loss of accuracy. We specifically present two incremental CORDIC-based multiply-accumulate architectures with an attempt to improve the accuracy performance trade-offs with each increment. A detailed Pareto analysis for 8and16-bit unsigned and signed multiply-accumulate structures is conducted to determine the optimum number of computing stages and the associated bit-precision of the intermediate results. Accuracy and performance analysis using 6th and 7th generation FPGA reveals a substantial improvement overstate-of-the-art designs. The proposed architectures are also tested using three image processing applications, and the output results are promising.
List of the following materials will be included with the Downloaded Backup: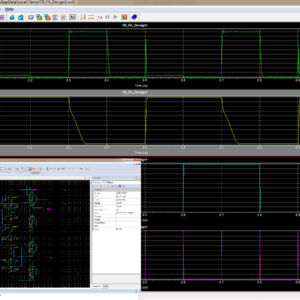
High-Speed Hybrid-Logic Full Adder Using High-Performance 10-T XOR–XNOR Cell
Abstract:
Hybrid logic style is widely used to implement full adder (FA) circuits. Performance of hybrid FA in terms of delay, power, and driving capability is largely dependent on the performance of XOR–XNOR circuit. In this article, a high speed, low-power 10-T XOR–XNOR circuit is proposed, which provides full swing outputs simultaneously with improved delay performance. The performance of the proposed circuit is measured by simulating it in cadence virtuoso environment using 90-nm CMOS technology. The proposed circuit reduces the power delay product (PDP) at least by 7.5% than that of the available XOR–XNOR modules. Four different designs of FAs are also proposed in this article utilizing the proposed XOR–XNOR circuit and available sum and carry modules. The proposed FAs provide 2%–28.13% improvement in terms of PDP than that of other architectures. To measure the driving capabilities, the proposed FAs are embedded in 2-, 4-, and 8-bit cascaded full adder (CFA) structures. Results show that two of the proposed FAs provide the best performance for a higher number of bits among all the FAs.
List of the following materials will be included with the Downloaded Backup:
Highly Linear Low-Power Wireless RF Receiver for WSN
Abstract:
This paper introduces a low-power wireless RF receiver for the wireless sensor network. The receiver has improved linearity with incorporated current-mode circuits and high-selectivity filtering. The receiver operates at the 900-MHz industrial, scientific, and medical band and is implemented in 130-nm CMOS technology. The receiver has a frequency multiplication mixer, which uses a 300-MHz clock from a local oscillator (LO). The LO is implemented using vertical delay cells to reduce power consumption. The receiver conversion gain is 40 dB and the receiver noise. The receiver’s input third-order intercept point (IIP3) is −6 dBm and the total power consumption is 1.16 mW.
List of the following materials will be included with the Downloaded Backup: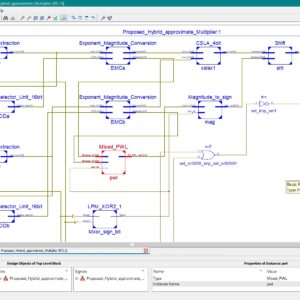
Hybrid Approximate Multipliers with Merits Balance for Digital Processing and Neural Networks
In this article, hybrid approximate multiplier (HAMs) designs based on the combination of logarithmic multiplication and piecewise linear (PWL) fitting are proposed. After extracting the exponent and mantissa of the input operands, two new variables are introduced to perform spatial mixed linear fitting on the 3-D surface of the mantissa product in different regions. Limited power-of-2 elements in line slopes make the multivariable mixed PWL computational simple and friendly to logic circuit complexity. With iterative adjustment of the slopes and bias of the lines in the PWL calculation, the relative error distance (RED) distribution is well balanced and zero concentrated. In addition, we detail the logic architecture to implement approximate hybrid accumulation and error tolerant complement conversions. In the 45-nm library-based performance comparison, the proposed multipliers mainly 16-, 8-, and 32-bit floating-point multipliers exhibit >55% power, >23% delay, and >43% area reductions compared with the exact multiplier. In addition, they outperform other state-of-the-art designs in terms of delay, power, area, and error, as evaluated by the joint delay–power–area product (PPA) and mean RED (MRED). In case experiments, the proposed multipliers perform nearly equivalently to the exact multiplier in error-tolerant digital processing and neural network computations. Index Terms Approximate multiplier, arithmetic digital circuit, computational logic architecture, logarithmic multiplier, piecewise linear (PWL).
List of the following materials will be included with the Downloaded Backup:
Hybrid Protection of Digital FIR Filters
Base Paper Abstract:
A digital finite impulse response (FIR) filter is a ubiquitous block in digital signal processing applications and its behavior is determined by its coefficients. To protect filter coefficients from an adversary, efficient obfuscation techniques have been proposed, either by hiding them behind decoys or replacing them by key bits. In this article, we initially introduce a query attack that can discover the secret key of such obfuscated FIR filters, which could not be broken by the existing prominent attacks. Then, we propose a first of its kind hybrid technique, including both hardware obfuscation and logic locking using a point function for the protection of parallel direct and transposed forms of digital FIR filters. Experimental results show that the hybrid protection technique can lead to FIR filters with higher security while maintaining the hardware complexity competitive or superior to those locked by prominent logic locking methods. It is also shown that the protected multiplier blocks and FIR filters are resilient to existing attacks. The results on different forms and realizations of FIR filters show that the parallel direct form FIR filter has a promising potential for a secure design.
List of the following materials will be included with the Downloaded Backup: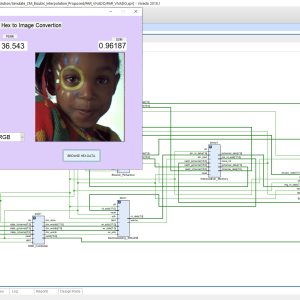
Image Demosaicking using Super Resolution Techniques
Base Paper Abstract:
Limitations do exist on capturing the full color information in a scene, apart from the resolution of captured images. Therefore, mosaic images are the preferred format in digital cameras, where incomplete set of color information is acquired. In this paper, a super resolution demosaicking (SRD) approach is proposed to reconstruct an enhanced-resolution full-color image from the observed samples, robustly and without the need for a training process. The acquisition model assumes degraded observations using known blur and noise. The reconstruction approach iteratively estimates the unknown registration parameters and the demosaicking image simultaneously. Qualitative and quantitative experiments performed on synthetic observations reveal high performance images.
List of the following materials will be included with the Downloaded Backup: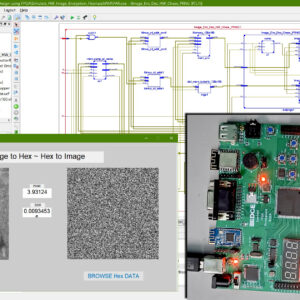
Image Encryption on FPGA Using Chaotic PRNG and LFSR: TFT Display Integration
Proposed Abstract:
Image encryption plays a crucial role in securing digital communication, especially with the rise of cyber threats and data breaches. This research focuses on implementing a Chaos-based Pseudorandom Number Generator (PRNG) for image encryption and compares its performance with Fibonacci and Galois-based Linear Feedback Shift Registers (LFSRs). The proposed system is developed using Verilog HDL and synthesized on a Xilinx Spartan-6 FPGA, with a real-time TFT display interface for encrypted and decrypted image visualization. Traditional LFSR-based PRNGs are widely used due to their simplicity and speed; however, they suffer from predictable periodicity and lower security strength. In contrast, Chaos-based PRNGs provide higher randomness and security, making them ideal for cryptographic applications. In this work, different PRNG approaches are analyzed based on randomness quality using the NIST test suite, hardware resource utilization (LUTs, FFs, power consumption), and encryption security (correlation, entropy, and key sensitivity). The Chaos-based PRNG is then integrated into a stream cipher encryption system, where image pixels are transformed using bitwise XOR and chaotic substitution-permutation operations. The encrypted images are decrypted using the inverse transformation and displayed on a TFT display, ensuring real-time validation. Experimental results confirm that the Chaos-based PRNG outperforms LFSR-based PRNGs in security strength and randomness, while maintaining efficient FPGA resource utilization. This work demonstrates a practical hardware-based image encryption system, suitable for real-time, secure multimedia applications such as IoT, medical imaging, and defense systems. Future enhancements include optimizing chaos-based PRNGs for high-speed cryptographic applications and exploring AI-based encryption techniques for enhanced security.
List of the following materials will be included with the Downloaded Backup:
Implementation of a Multipath Fully Differential OTA in 0.18-μm CMOS Process
Base Paper Abstract:
This brief implements a highly efficient fully differential trans conductance amplifier, based on several input-to-output paths. Some traditional techniques, such as positive feedback, nonlinear tail current sources, and current mirror-based paths, are combined to increase the trans conductance, thus leading to larger dc gain and higher gain bandwidth (GBW) product. Two flipped voltage-follower (FVF) cells are employed as variable current sources to provide class-AB operation and adaptive biasing of all other drivers. The proposed structure includes several input-to-output paths that play the role of dynamic current boosters during the slewing phase, thus improving the slew rate (SR) performance. The circuit was fabricated in a TSMC 0.18-µm CMOS process with a silicon area of 54.5 × 30.1 µm. Experimental results show a GBW of 173.3 MHz, a dc gain of 72.7 dB, and an SR of 139.4 V/µs for a capacitive load of 2 × 5 pF. The proposed circuit consumes 619 µW of power, under a supply voltage of 1.8 V.
List of the following materials will be included with the Downloaded Backup:
Implementation of High-Precision MFCC Feature Extraction Using FPGA for Speech Recognition
Proposed Abstract:
Speaker recognition is one of the technologies that may be used for biometric identification, and it offers higher application possibilities in many sectors. At the moment, the implementation of the speaker identification algorithm on the hardware is mostly dependent on the SOC of the FPGA. An FPGA-based real-time technique for extracting acoustic characteristics is presented in this research. The method is based on MFCC, which stands for Mel Frequency Cepstral Coefficients. The trials have shown that the FPGA-based MFCC calculation has a high level of accuracy; the purpose of this study is to enhance the performance assessment of MFCC by making use of novelty-based architecture. In this study, a technique for FPGA-based speech recognition is provided. This approach was developed by investigation and analysis of the speaker recognition algorithm. The IFFT, the Mell filter, the DFT, the derivatives, and the Hamming Window with pre-emphasis are every aspect of this approach. This proposed MFCC will be constructed with an AHB interface in order to facilitate higher access DMA Controller when it is used in SOC applications. This work was carried out using Verilog HDL, and it was generated with Xilinx Vivado FPGA. Additionally, all of the parameters were analyzed and compared with regard to area, latency, and power.
List of the following materials will be included with the Downloaded Backup:
Implementation of Low Power 1-bit Hybrid Full Adder using 22nm CMOS Technology
Abstract:
Adders are plays a vital role in digital and vlsi systems. Arithmetic operations are an essential part of digital systems. During VLSI systems, the entire research is on lowering the scale of transistors for enforcing any other digital system. This proposed architecture implemented by different types of logic systems; each logic performs the different role in the hybrid system. The hybrid Full Adder cell with one bit is implemented in this structure. The proposed method is investigated using 22-nm CMOS hybrid full adder. The proposed architecture demonstrates substantial efficiency in power consumption and delay, based on simulation results. The simulation result expressed that the full adder circuit is used to modern high speed central processing unit in the data path architecture. This form of hybrid Full Adder, reduces the delay and increasing efficiency and mainly used in nano technology applications. The average power consumption of 1.1055uW with moderately low delay of 7.0415 ps was found to be extremely low for 0.8-V supply at 22-nm technology. These kind of adder allocates significant improvements in power, high speed and area compared with previous full adder designs.
List of the following materials will be included with the Downloaded Backup:
Implementation of Subthreshold Adiabatic Logic for Ultralow Power Application
Abstract:
The Subthreshold adiabatic logic for Ultralow power application is a novel approach is efficient in low speed operations, where power consumption and longevity are the pivotal concerns instead of performance. Here, we are implementing the adiabatic logic gates and implementing CLA 8-bit, it will compared to the normal logic gates, the adiabatic logic makes a more power consumption and also increasing speed. The schematic and layout of a 4-bit carry look ahead adder (CLA) has been implemented to show the workability of the proposed logic. The effect of temperature and process parameter variations on sub threshold adiabatic logic-based 4-bit CLA has also been addressed separately. Post layout simulations show that sub threshold adiabatic units can save significant energy compared with a logically equivalent static CMOS implementation.
List of the following materials will be included with the Downloaded Backup: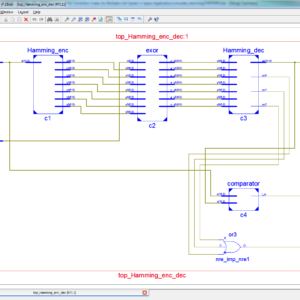
Improving Error Correction Codes for Multiple-Cell Upsets in Space Applications
Proposed Abstract:
Currently, faults suffered by SRAM memory systems have increased due to the aggressive CMOS integration density. Thus, the probability of occurrence of single-cell upsets (SCUs) or multiple-cell upsets (MCUs) augments. One of the main causes of MCUs in space applications is cosmic radiation. A common solution is the use of error correction codes (ECCs). Nevertheless, when using ECCs in space applications, they must achieve a good balance between error coverage and redundancy, and their encoding/decoding circuits must be efficient in terms of area, power, and delay. Different codes have been proposed to tolerate MCUs. For instance, Matrix codes use Hamming codes and parity checks in a bi-dimensional layout to correct and detect some patterns of MCUs. Recently presented, column–line–code (CLC) has been designed to tolerate MCUs in space applications. CLC is a modified Matrix code, based on extended Hamming codes and parity checks. Nevertheless, a common property of these codes is the high redundancy introduced. In this paper, we present a series of new low redundant ECCs able to correct MCUs with reduced area, power, and delay overheads. Also, these new codes maintain, or even improve, memory error coverage with respect to Matrix and CLC codes.
List of the following materials will be included with the Downloaded Backup:
In-Field Test for Permanent Faults in FIFO Buffers of NoC Routers
Abstract:
This brief proposes an on-line transparent test technique for detection of latent hard faults which develop in first input first output buffers of routers during field operation of NoC. The technique involves repeating tests periodically to prevent accumulation of faults. A prototype implementation of the proposed test algorithm has been integrated into the router-channel interface and on-line test has been performed with synthetic self-similar data traffic. The performance of the NoC after addition of the test circuit has been investigated in terms of throughput while the area overhead has been studied by synthesizing the test hardware. In addition, an on-line test technique for the routing logic has been proposed which considers utilizing the header flits of the data traffic movement in transporting the test patterns.
List of the following materials will be included with the Downloaded Backup:
Input Based Dynamic Reconfiguration of Approximate Arithmetic Units for Video Encoding
Abstract:
The field of approximate computing has receivedsignificant attention from the research community in the pastfew years, especially in the context of various signal processingapplications. Image and video compression algorithms, such asJPEG, MPEG, and so on, are particularly attractive candidatesfor approximate computing, since they are tolerant of computingimprecision due to human imperceptibility, which can beexploited to realize highly power-efficient implementations ofthese algorithms. However, existing approximate architecturestypically fix the level of hardware approximation staticallyand are not adaptive to input data. For example, if afixed approximate hardware configuration is used for anMPEG encoder (i.e., a fixed level of approximation), theoutput quality varies greatly for different input videos. Thispaper addresses this issue by proposing a reconfigurableapproximate architecture for MPEG encoders thatoptimizespower consumption with the goal of maintaining a particularPeak Signal-to-Noise Ratio (PSNR) threshold for any video.We propose two heuristics for automaticallytuning the approximation degree of the RABs in thesetwo modules during runtime based on the characteristics of eachindividual video. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Instantaneous Power Consuming Level Shifter for Improving Power Conversion Efficiency of Buck Converter
Abstract:
An instantaneous power consuming level shifter is presented in this paper to increase the DC converter efficiency. The level shifter is used in a high-side power switch driver to remove the external capacitor which is used in bootstrap technique. The level shifter consumes power only during the transition period. A delay cell is used to turn the level shifter off to reduce the power consumption period. An output voltage detector is added to turn the level shifter off even before the delay time. An asynchronous discontinuous conduction mode buck converter is designed to verify the performance of the level shifter. Simulation results show that the power consumption of the proposed level shifter decreased by 66%, while the converter efficiency increased by the maximum of 9% compared to results obtained for a conventional level shifter. The converter is fabricated using the TSMC 0.18-µm BCD process and it operates within an input range of 2–5 V when the current varies from 400 µA to 18 mA and delivers an output voltage of 1.8 V.
List of the following materials will be included with the Downloaded Backup: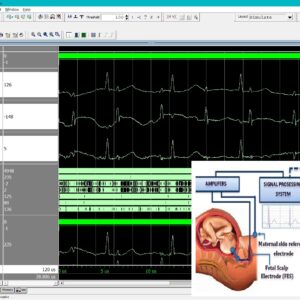
Invasive RLS-Based Fetal ECG Extraction with Optimized Shift-and-Add Multiplier for Area-Efficient FPGA Implementation
Base Paper Abstract:
This article proposes a fetal electrocardiogram (FECG) separation approach based on an energy-dependent recursive least-square (RLS) filtering approach that uses the mother’s R-peaks collected from both the abdomen and the thorax. This approach initially identifies the mother’s R-peaks from the thorax electrocardiogram (ECG), which is used to represent the mother’s R-peaks in both the abdominal and thorax channels. Instead of using the recent abdominal and thorax ECG (TECG) samples, the proposed filter also considers the energy of L1 number of mother’s past R-peak abdominal and thorax samples along with the energy of L2 number of non-R-peak abdominal samples for estimating the R-peak energy factor. The energy factor is estimated for each sample for the updating of weights in the RLS filter. An architecture for the filter is also proposed, which can be used in hardware implementation. The evaluation of the proposed filtering approach was performed using datasets such as Synthetic and Daisy with the evaluation metrics, namely, correlation coefficient, fetal R-peak detection accuracy (PDA), fetal-to-maternal signal-to-noise ratio (SNR), and percent root-mean-square difference. With filter length P = 24, the proposed filter results in correlation, SNR, and percent root-mean-square difference of 0.9901, 9.03 dB, and 80.84%, respectively. For the Daisy and Synthetic datasets, the PDA was estimated as 96.4% and 98.12% respectively. The architecture of the proposed filter was implemented in Virtex VC707 hardware, which utilizes a power of 1.378 W, resulting in a maximum clock frequency and throughput (TP) of 128.43 MHz and 31.5 Mb/s, respectively, with a word length of L = 24 bits.
List of the following materials will be included with the Downloaded Backup:
JF-Cut: A Parallel Graph Cut Approach for Large-Scale Image and Video
Graph cut has proven to be an effective scheme to solve a wide variety of segmentation problems in vision and graphics community. The main limitation of conventional graph-cut implementations is that they can hardly handle large images or videos because of high computational complexity. Even though there are some parallelization solutions, they commonly suffer from the problems of low parallelism (on CPU) or low convergence speed (on GPU). In this paper, we present a novel graph-cut algorithm that leverages a parallelized jump flooding technique and an heuristic push-relabel scheme to enhance the graph-cut process, namely, back-and-forth relabel, convergence detection, and block-wise push-relabel. The entire process is parallelizable on GPU, and outperforms the existing GPU-based implementations in terms of global convergence, information propagation, and performance. We design an intuitive user interface for specifying interested regions in cases of occlusions when handling video sequences. Experiments on a variety of data sets, including images (up to 15 K×10 K), videos (up to 2.5K×1.5K×50), and volumetric data, achieve highquality results and a maximum 40-fold (139-fold) speedup over conventional GPU (CPU-)-based approaches.
List of the following materials will be included with the Downloaded Backup:
LECTOR: A Technique for Leakage Reduction in CMOS Circuits
Abstract:
In CMOS circuits, the reduction of the threshold voltage due to voltage scaling leads to increase in sub threshold leakage current and hence static power dissipation. We propose a novel technique called LECTOR for designing CMOS gates which significantly cuts down the leakage current without increasing the dynamic power dissipation. In the proposed technique, we introduce two leakage control transistors (a p-type and a n-type) within the logic gate for which the gate terminal of each leakage control transistor (LCT) is controlled by the source of the other. In this arrangement, one of the LCTs is always “near its cutoff voltage” for any input combination. This increases the resistance of the path from to ground, leading to significant decrease in leakage currents. The gate-level net list of the given circuit is first converted into a static CMOS complex gate implementation and then LCTs are introduced to obtain a leakage-controlled circuit. The significant feature of LECTOR is that it works effectively in both active and idle states of the circuit, resulting in better leakage reduction compared to other techniques. Further, the proposed technique overcomes the limitations posed by other existing methods for leakage reduction. Experimental results indicate an average leakage reduction of 79.4% for MCNC’91 benchmark circuits.
List of the following materials will be included with the Downloaded Backup:
Level-Converting Retention Flip-Flop for Reducing Standby Power in ZigBee SoCs
Abstract: In this paper, we are proposed a level converting retention flip-flop for Zigbee Soc, it will be using to allows the voltage regulator that generates the core supply voltage (VDD, core), to be turned off in the standby mode, and it thus reduces the standby power of the Zigbee Soc. Here the Level up conversion form VDD core is achieved by and embedded nMOS pass transistor level-conversion scheme that uses a low only signal transmitting technique. By embedding a retention latch and level-up converter into the data-to-output path of the proposed RFF, the RFF resolves the problems of the static RAM-based RFF, such as large dc current and low readability caused by threshold drop. The proposed RFF does not also require additional control signals for power mode transitioning. Using 0.13-μm process technology, we implemented an RFF with VDD,core and VDD,IO of 1.2 and 2.5 V, respectively. The maximum operating frequency is 300 MHz. The active energy of the RFF is 191.70 fJ, and its standby power is 350.25 pW.
List of the following materials will be included with the Downloaded Backup:
Lightweight, High-Entropy TRNG Using Quad Cross-Coupled Feedback Architecture
Base Paper Abstract:
This paper presents a lightweight, high-entropy true random number generator architecture featuring an innovative quad cross-coupled feedback mechanism to enhance randomness. The primary goal is to develop an efficient and secure true random number generator that addresses the growing demand for reliable random number generation in cryptographic and security-critical applications. The motivation stems from the need to improve entropy, reduce resource utilization, and ensure robustness across varying technologies. With the intention of achieving near-perfect randomness, the Quad-Input Oscillating Circuit module integrates self-coupled, jitter-inducing ring oscillators with cross-coupled feedback loops to induce metastability. Comprehensive evaluations confirm a Shannon entropy of 0.999818, a minimum entropy of 0.977257, and a collision entropy of 0.999636. The design was synthesized using Synopsys Design Compiler at 45 nm, 32 nm, and 14 nm, achieving a maximum frequency of 6.7 GHz, power consumption as low as 72 μW, and area utilization of 24 μm2 at 14 nm. Rigorous validation through multiple statistical test suites, including the AIS-31, Autocorrelation, Deviation, Diehard, the National Institute of Standards and Technologies SP800- 22 and SP800-90B, and TestU01, confirms its efficiency and reliability. Real random bits were implemented as oscilloscope viewable signals on the Cyclone V Field Programmable Gate Array developed by Altera, representing a significant advancement in secure random number generation technologies.
List of the following materials will be included with the Downloaded Backup:
Line Coding Techniques for Channel Equalization: Integrated Pulse-Width Modulation and Consecutive Digit Chopping
Abstract:
This paper presents two new line-coding schemes, integrated pulse width modulation (iPWM) and consecutive digit chopping (CDC) for equalizing lossy wire line channels with the aim of achieving energy efficient wire line communication. The proposed technology friendly encoding schemes are able to overcome the fundamental limitations imposed by Manchester or pulse-width modulation encoding on high-speed wire line transceivers. A highly digital encoder architecture is leveraged to implement the proposed iPWM and CDC encoding. Energy-efficient operation of the proposed encoding is demonstrated on a high-speed wire line transceiver that can operate from 10 to 18 Gb/s. Fabricated in a 65-nm CMOS process, the transceiver operates with supply voltages of 0.9 V, 1 V, and 1.1 V. With the help of the proposed iPWM encoding, the transceiver can equalize over 27-dB of channel loss while operating at 16 Gb/s with an efficiency of 4.37 pJ/bit. The design occupies an active die area of 0.21 mm2.
List of the following materials will be included with the Downloaded Backup: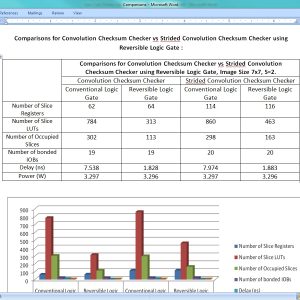
Low Cost Online Convolution Checksum Checker
Abstract:
Managing random hardware faults requires the faults to be detected online, thus simplifying recovery. Algorithm-based fault tolerance has been proposed as a low-cost mechanism to check online the result of computations against random hardware failures. In this case, the checksum of the actual result is checked against a predicted checksum computed in parallel by a hardware checker. In this work, we target the design of such checkers for convolution engines that are currently the most critical building block in image processing and computer vision applications. The proposed convolution checksum checker, named ConvGuard, utilizes a newly introduced invariance condition of convolution to predict implicitly the output checksum using only the pixels at the border of the input image. In this way, ConvGuard reduces the power required for accumulating the input pixels without requiring large buffers to hold intermediate checksum results. The design of ConvGuard is generic and can be configured for different output sizes and strides. The experimental results show that ConvGuard utilizes only a small percentage of the area/power of an efficient convolution engine while being significantly smaller and more power efficient than a state-of-the-art checksum checker for various practical cases.
List of the following materials will be included with the Downloaded Backup: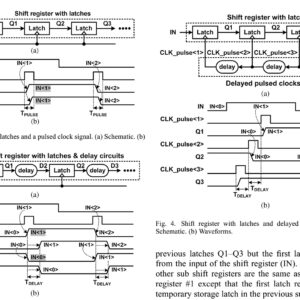
Low Power and Area Efficient Shift Register Using Pulsed Latches
Abstract: This paper proposes a low-power and area-efficient shift register using pulsed latches. The area and power consumption are reduced by replacing flip-flops with pulsed latches. This method solves the timing problem between pulsed latches through the use of multiple non-overlap delayed pulsed clock signals instead of the conventional single pulsed clock signal. The shift register uses a small number of the pulsed clock signals by grouping the latches to several sub shifter registers and using additional temporary storage latches. The proposed architecture of this paper analysis the area and power using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Low Power and High Speed Implementation of FIR filter design using CMOS GDI Truncated Multiplier
Abstract:
The logic size, propagation delay, power of applications, based upon this improvement the adder design logic size will reduced year by year, here a proposed In recent technology of any application, adders is a more priority to do a function and task of arithmetic operation, in crucial this adder based arithmetic operation will decide work of this paper will design using a single bit full adder to design a multiplier. In this multiplier design, adder is a main priority to reduce the arithmetic logic size and increases speed of multiplier, in recent we have lots of multiplier design, Vedic multiplier, Wallace tree multiplier, booth multiplier, approximate multiplier. Here, the proposed work will taken truncated multiplier design, it's because, the truncated multiplier will have a capability to reduced internal and external architecture size in every design, regarding this truncated multiplier will have three options such as rounding, deleting, truncating, here the MSB bits will be truncated and present the output of n x n multiplication will provided only n bit level, using this truncated multiplier the proposed work will designed a 8-Tap FIR(Finite impulse response) filter and shown the efficiency of filter design using this CMOS GDI (Gate Diffusion Input) adder design. This proposed work will design in CMOS Logic gate and which 10-T transistor level of full adders with 90um technology, finally proved the terms of area, delay and power.
List of the following materials will be included with the Downloaded Backup:
Low Power Compressor Based MAC Architecture for DSP Applications
This paper presents the low power compressor based Multiply-Accumulate (MAC) architecture for DSP applications. In VLSI, highly computed arithmetic cells including adders and multipliers are the most copiously used components. Efficient implementation of arithmetic logic units, floating point units and other dedicated functional components are utilized in most of the microprocessors and digital signal processors (DSPs). Thus in this brief, compressor circuit has been illustrated for the low power applications and also the impact of datapath circuits has been demonstrated. The proposed low power compressor architecture was applied to MAC unit and compared against the conventional compressor based MAC units and observed that the proposed architecture has reduced significant amount of leakage power. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
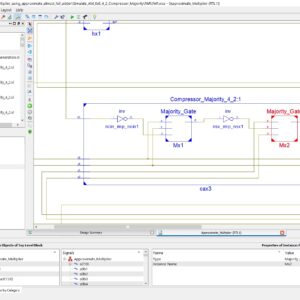
Low power Dadda multiplier using approximate almost full adder and Majority logic based adder compressors
Base Paper Abstract:
An Approximate computing is widely used to have energy-efficient system design in Very Large-Scale Integration (VLSI). This approach is best suited for signal processing and multimedia applications where low power consumption is the main concern. Faster and significant results can be obtained from an approximate computing at the cost of reduced accuracy. In this work, we proposed a very novel design approaches based on various monolithic 4:2 compressors. Proposed approach is applied to have reduced stages in the partial product multiplication. Proposed Monolithic compressor had outperformed over various 4:2 compressors. Our proposed method is based on majority logic based with the use of Dadda multiplication. A new-partial product reduction format is implemented by this multiplier, which reduces the maximum output delay. This method of approach significantly reduces the utilization of number of MOSFETs compared to other multiplier such as Wallace Tree Multipliers. Simulation results are compared with conventional Dadda multiplier and ML based 4:2 compressors. Proposed approximate computing based almost full adder based majority logic based Dadda multiplier achieves reduction of 60.93% in area utilization 72.48% reduction in dynamic power reduction while processing time is also reduced by 72.98%. Dadda multiplication outperforms the other compressors.
List of the following materials will be included with the Downloaded Backup:
Low Power Divider Using Vedic Mathematics
Vedic mathematics is a unique technique of carrying out mathematical computations and it has its roots in the ancient Indian Mathematics. This paper presents the divider architecture using one of the Vedic mathematics techniques called as Paravartya-Yojayet, which means to transpose and apply. This paper proposes a fast, low power and cost effective architecture of a divider using the ancient Indian Vedic division algorithm. The merits of the proposed architecture are proved by comparing the gate count, power consumption and delay against the conventional divider architectures. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup: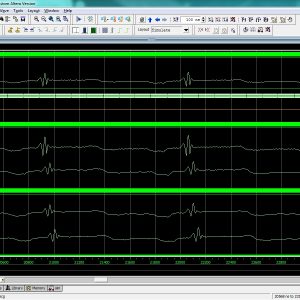
Low Power ECG Based Processor for Predicting Ventricular Arrhythmia
This paper presents the design of a fully integrated electrocardiogram (ECG) signal processor (ESP) for the prediction of ventricular arrhythmia using a unique set of ECG features and a naive Bayes classifier. Real-time and adaptive techniques for the detection and the delineation of the P-QRS-T waves were investigated to extract the fiducial points. We are also detecting the all interval in the ECG signal and compare the stored record for Ventricular Arrhythmia with also energy/area architecture design. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Low Power FPGA Design Using Memoization Based Approximate Computing
Field-programmable gate arrays (FPGAs) are increasingly used as the computing platform for fast and energy efficient execution of recognition, mining, and search applications. Approximate computing is one promising method for achieving energy efficiency. Compared with most prior works on approximate computing, which target approximate processors and arithmetic blocks, this paper presents an approximate computing methodology for FPGA-based design. It studies memoization as a method for approximation on FPGA and analyzes different architectural and design parameters that should be considered. The proposed design flow leverages on high-level synthesis to enable memoization-based microarchitecture generation, thus also facilitating a C-to-register-transfer-level synthesis. When compared with the previous approaches of bit-width truncation and approximate multipliers, memoization-based approximate computation on FPGA achieves a significant dynamic power saving (around 20%) with very small area overhead (<5%) and better power-to-signal noise ratio values for the studied image processing benchmarks. The proposed architecture of this paper is verified using vivado HLS..
List of the following materials will be included with the Downloaded Backup:
Low Power Split Radix FFT Processors Using Radix 2 Butterfly Units
Split radix fast Fourier Transform (SRFFT) is an ideal candidate for the implementation of a low power FFT processor, because it has the lowest number of arithmetic operation among all the FFT algorithms. In the design of such processors, an efficient addressing scheme for FFT data as well as twiddle factors is required. The signal flow graph of SRFFT is the same as radix-2 FFT, and therefore, the conventional address generation schemes of FFT data could also be applied to SRFFT. However SRFFT has irregular locations of twiddle factors and forbids the application of radix-2 address generation methods. This brief presents a shared memory low power SRFFT processor architecture. The SRFFT can be computed by using a modified radix-2 butterfly unit. The butterfly unit exploits the multiplier-gating technique to save dynamic power at the expense of using more hardware resources. In addition, two novel address generation algorithm for both the trivial and nontrivial twiddle factors are developed. In this paper We increases the architecture size, of radix-4 and 2048 point complex valued transform, and shown the performance of area, power and delay, and synthesized xilinx FPGA on s6lx16-2csg225.
List of the following materials will be included with the Downloaded Backup: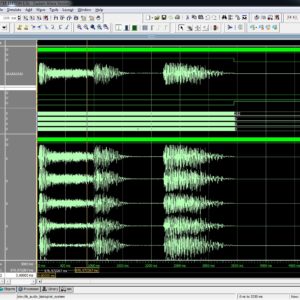
Low Power System for Detection of Symptomatic Patterns in Audio Biological Signals
We present a low-power, efficacious, and scalable system for the detection of symptomatic patterns in biological audio signals. The digital audio recordings of various symptoms, such as cough, sneeze, and so on, are spectrally analyzed using a discrete wavelet transform. Subsequently, we use simple mathematical metrics, such as energy, quasi-average, and coastline parameter for various wavelet coefficients of interest depending on the type of pattern to be detected. Furthermore, a mel-frequency cepstrum-based analysis is applied to distinguish between signals, such as cough and sneeze, which have a similar frequency response and, hence, occur in common wavelet coefficients. Algorithm-circuit codesign methodology is utilized in order to optimize the system at algorithm and circuit levels of design abstraction. This helps in implementing a low-power system as well as maintaining the efficacy of detection. The system is scalable in terms of user specificity as well as the type of signal to be analyzed for an audio symptomatic pattern. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Low Power Variation Tolerant Nonvolatile Lookup Table Design
Emerging nonvolatile memories (NVMs), such as MRAM, PRAM, and RRAM, have been widely investigated to replace SRAM as the configuration bits in field-programmable gate arrays (FPGAs) for high security and instant power ON. However, the variations inherent in NVMs and advanced logic process bring reliability issue to FPGAs. This brief introduces a low-power variation-tolerant nonvolatile lookup table (nvLUT) circuit to overcome the reliability issue. Because of large ROFF/RON, 1T1R RRAM cell provides sufficient sense margin as a configuration bit and a reference resistor. A single-stage sense amplifier with voltage clamp is employed to reduce the power and area without impairing the reliability. Matched reference path is proposed to reduce the parasitic RC mismatch for reliable sensing. Evaluation shows that 22% reduction in delay, 38% reduction in power, and the tolerance of variations of 2.5× typical RON or ROFF in reliability are achieved for proposed nvLUT with six inputs. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Low voltage high speed 8T SRAM cell for ultra-low power applications
Proposed Abstract:
The usage of portable devices increasing rapidly in the modern life has led us to focus our attention to increase the performance of the SRAM circuits, especially for low power applications. Basically in Six-Transistor (6T) SRAM cell either read or write operation can be performed at a time whereas, in 7T SRAM cell using single ended write operation and single ended read operation both write and read operations will be accomplished simultaneously at a time respectively. When it comes to operate in sub threshold region, single ended read operation will be degraded severely and single ended write operation will be severely degraded in terms of write-ability at lower voltages. To encounter these complications, an eight transistor SRAM cell is proposed. It performs single ended read operation and single ended write operation together even at sub threshold region down to 0.1V with improved read-ability using read assist and improved dynamic write-ability which helps in reducing the consumption of power by attaining a lower data retention voltage point. To reduce the total power consumption in the circuits, two extra access transistors are used in 8T SRAM cell which also helps in reducing the overall delay.
List of the following materials will be included with the Downloaded Backup:
Low-Complexity 2-D Digital FIR Filters Using Polyphase Decomposition and Farrow Structure
Abstract:
This paper proposes a novel realization technique for quadrantally symmetric 2-D finite impulse response filters with a guaranteed reduction in the hardware complexity. Here, the concept of Farrow structure-based interpolation filter design using the polyphase decomposition of the 1-D filter transfer function is effectively utilized in the 2-D domain. The proposed 2-D filter makes use of row-wise polyphase decomposition of the 2-D transfer function or frequency response, followed by the polynomial approximation of the individual polyphase coefficients resulting in Farrow structures corresponding to each row filter. The final coefficients are implemented by varying the delay values in all the Farrow structures, followed by the interpolation of the coefficients obtained from each delay value, which in turn forms the rows in the 2-D kernel. The major highlight of the proposed method is the highly reduced implementation complexity in terms of the number of multipliers and adders, with a low normalized root-mean-square error. Design examples of the circularly symmetric and fan-type filters have been considered to show the efficiency of the approach. The results show a drastic reduction in the implementation complexity of the 2-D filters of upto 20%, with significantly low normalized root-mean-square error lesser than 0.5%.
List of the following materials will be included with the Downloaded Backup: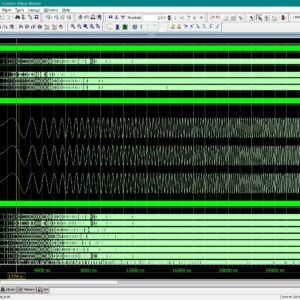
Low-Complexity Implementation of Real-Time Reconfigurable Low-Pass Equalizers
Implementation techniques and results for a recently proposed real-time reconfigurable low-pass equalizer (RLPE) consisting of a variable bandwidth (VBW) filter and a variable equalizer (VE) are presented. Both components utilize fixed finite-length impulse response (FIR) filters combined with a few general multipliers, resulting in lower area and power consumption compared to a general FIR filter, despite requiring more multiplications. This is because the constant multipliers in the fixed FIR filters of the RLPE can be optimized for implementation. An additional advantage is that the proposed RLPE does not require online design. Various implementation alternatives for fixed FIR filters, including ways to increase the frequency, are evaluated to optimize the implementation of the RLPE. Several versions of the proposed RLPE and a general FIR filter for comparison are implemented using a 28-nm fully depleted silicon on insulator (FD-SOI) standard cell library. The results demonstrate that the RLPE baseline design requires less power and area than the general equalizer, and although the frequency of the baseline implementation is lower, the design can reach the same frequency while still having significantly less power and area. Furthermore, an approach is introduced to break the chain in the polynomial section of the VBW filter by using fewer additional registers compared to standard pipelining. Instead, this method reformulates the constant multiplication problem to produce correct results. For the considered case, the power consumption is reduced between 49% and 70% for different frequencies, with an area decrease in the range of 64% to 67%, by using the proposed RLPE compared to a general FIR filter. Index Terms: Constant multiplications, real-time reconfiguration, variable bandwidth (VBW) low-pass filter, variable equalizer (VE).
List of the following materials will be included with the Downloaded Backup: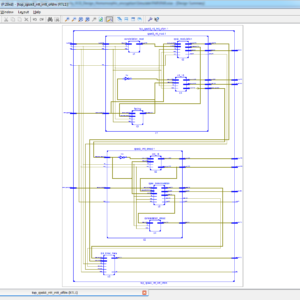
Low-Complexity VLSI Design of Large Integer Multipliers for Fully Homomorphic Encryption
Abstract:
Large integer multiplication has been widely used in fully homomorphic encryption (FHE). Implementing feasible large integer multiplication hardware is thus critical for accelerating the FHE evaluation process. In this paper, a novel and efficient operand reduction scheme is proposed to reduce the area requirement of radix-r butterfly units. We also extend the single port, merged-bank memory structure to the design of number theoretic transform (NTT) and inverse NTT (INTT) for further area minimization. In addition, an efficient memory addressing scheme is developed to support both NTT/INTT and resolving carries computations. Experimental results reveal that significant area reductions can be achieved for the targeted 786 432- and 1 179 648-bit NTT-based multipliers designed using the proposed schemes in comparison with the related works. Moreover, the two multiplications can be accomplished in 0.196 and 2.21 ms, respectively, based on 90-nm CMOS technology. The low-complexity feature of the proposed large integer multiplier designs is thus obtained without sacrificing the time performance.
List of the following materials will be included with the Downloaded Backup: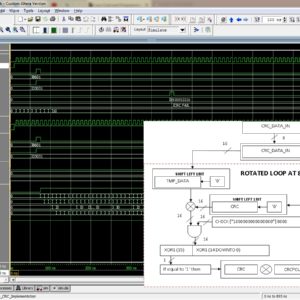
Low-Cost and Programmable CRC Implementation Based on FPGA
Abstract:
Cyclic redundancy check (CRC) is a well-known error detection code that is widely used in Ethernet, PCIe, and other transmission protocols. The existing FPGA-based implementation solutions encounter the problem of excessive resource utilization in high-performance scenarios. The padding zeros problem and the introduction of programmability further exacerbate this problem. In this brief, the stride-by-5 algorithm is proposed to achieve the optimal utilization of FPGA resources. The pipelining go back algorithm is proposed to solve the padding zeros problem. The method of reprogramming by HWICAP is proposed to realize programmability with small and constant resource utilization. The experimental results show that the resource utilization of the proposed non-segmented architecture is 80.7%-87.5% and 25.1%-46.2% lower than that of two state of-the-art FPGA-based CRC implementations, and the proposed segmented architecture has lower resource utilization, by 81.7%- 85.9% and 2.9%-20.8%, than two state-of-the-art architectures. Furthermore, throughput and programmability are guaranteed.
List of the following materials will be included with the Downloaded Backup: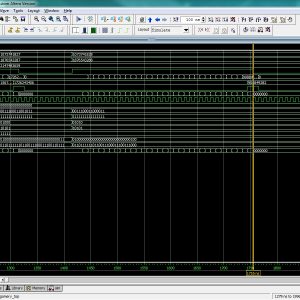
Low-Cost High-Performance VLSI Architecture for Montgomery Modular Multiplication
Source Code : VHDL & VERILOG HDL
Abstract: This paper proposes a simple and efficient Montgomery multiplication algorithm such that the low-costand high-performance Montgomery modular multiplier can be implemented accordingly. The proposed multiplier output data with representation and uses only one parallel prefix adder to avoid a carry propagation and reduce the area, power and delay, and also increasing the speed. Mainly the usage of parallel prefix adder is to reduce the significant delay reduction and area × time2 improvements, all this at the cost of higher power consumption, which is the main reason preventing the use of parallel-prefix adders to achieve high-speed reverse converters in nowadays systems. Hence, to solve the high power consumption problem, novel specific hybrid parallel-prefix-based adder components those provide better trade-off between delay and power consumption. As a result, the extra clock cycles for operand pre-computation and format conversion can be hidden and high throughput can be obtained. Experimental results show that the proposed Montgomery modular multiplier can achieve higher performance and significant area–time product improvement when compared with previous designs. Using VHDL to design the RTL, and the result to be shown in Xilinx 14.2 with Power consumption and area reduction.
List of the following materials will be included with the Downloaded Backup:
Low-Energy Power-ON-Reset Circuit for Dual Supply SRAM
Design of a low-energy power-ON reset (POR) circuit is proposed to reduce the energy consumed by the stable supply of the dual supply static random access memory (SRAM), as the other supply is ramping up. The proposed POR circuit, when embedded inside dual supply SRAM, removes its ramp-up constraints related to voltage sequencing and pin states. The circuit consumes negligible energy during ramp-up, does not consume dynamic power during operations, and includes hysteresis to improve noise immunity against voltage fluctuations on the power supply. The POR circuit, designed in the 40-nm CMOS technology within 10.6-µm2 area, enabled 27× reduction in the energy consumed by the SRAM array supply during periphery power-up in typical conditions. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Low-Power and Fast Full Adder by Exploring New XOR and XNOR Gates
Abstract:
In this paper, novel circuits for XOR/XNOR and simultaneous XOR–XNOR functions are proposed. The proposed circuits are highly optimized in terms of the power consumption and delay, which are due to low output capacitance and low short-circuit power dissipation. We also propose six new hybrid 1-bit full-adder (FA) circuits based on the novel full-swing XOR–XNOR or XOR/XNOR gates. Each of the proposed circuits has its own merits in terms of speed, power consumption, power delay product (PDP), driving ability, and so on. To investigate the performance of the proposed designs, extensive HSPICE and Cadence Virtuoso simulations are performed. The simulation results, based on the 65-nm CMOS process technology model, indicate that the proposed designs have superior speed and power against other FA designs. A new transistor sizing method is presented to optimize the PDP of the circuits. In the proposed method, the numerical computation particle swarm optimization algorithm is used to achieve the desired value for optimum PDP with fewer iterations. The proposed circuits are investigated in terms of variations of the supply and threshold voltages, output capacitance, input noise immunity, and the size of transistors.
List of the following materials will be included with the Downloaded Backup:
Low-Power and High-Speed SRAM Cells With Double-Node Upset Self-Recovery for Reliable Applications
Transistor sizing and spacing are constantly decreasing due to the continuous advancement of CMOS technology. The charge of the sensitive nodes in the static random access memory (SRAM) cell gradually decreases, making the SRAM cell more and more sensitive to soft errors, such as single node upsets (SNUs) and double node upsets (DNUs). Therefore, two types of radiation-hardened SRAM cells are proposed in this article. First, a low-power DNU self-recovery S6P8N cell is proposed. This cell can realize SNU self-recovery from all sensitive nodes as well as realize partial DNUs self-recovery and has low-power consumption overhead. Second, we propose a high-speed DNU self-recovery S8P6N cell, which has a soft-error tolerance level similar to the S6P8N. Furthermore, it reduces the read access time (RAT) and write access time (WAT). Simulation results show that the proposed cells are self-recovery for all SNUs and most of DNUs. Compared with RHD12, QCCM12T, QUCCE12T, RHMD10T, SEA14T, RHM-12T, S4P8N, S8P4N, RH-14T, HRLP16T, CC18T, and RHM, the average power consumption of S6P8N is reduced by 48.78%, and the average WAT is reduced by 6.62%. While the average power consumption of S8P6N is reduced by 23.64%, and the average WAT and RAT by 9.07% and 36.84%, respectively. Index Terms: Double-node upsets (DNUs), high-speed, low power, self-recovery, static random access memory (SRAM).
List of the following materials will be included with the Downloaded Backup: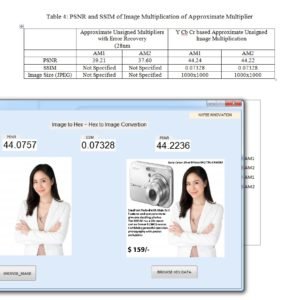
Low-Power Approximate Unsigned Multipliers with Configurable Error Recovery
Abstract:
Approximate circuits have been considered for applications that can tolerate some loss of accuracy with improved performance and/or energy efficiency. Multipliers are key arithmetic circuits in many of these applications including digital signal processing (DSP). In this paper, a novel approximate multiplier with a low power consumption and a short critical path is proposed for high-performance DSP applications. This multiplier leverages a newly designed approximate adder that limits its carry propagation to the nearest neighbors for fast partial product accumulation. Different levels of accuracy can be achieved by using either OR gates or the proposed approximate adder in a configurable error recovery. The multipliers using these two error reduction strategies are referred to as approximate multiplier 1 (AM1) and approximate multiplier 2 (AM2), respectively. Both AM1 and AM2 have a low mean error distance, i.e., most of the errors are not significant in magnitude. Compared to a Wallace multiplier optimized for speed, an 8×8 AM1 with 4 MSBs (most significant bits) for error reduction and synthesized using a 28 nm CMOS process shows a 60% reduction in delay (when optimized for delay) and a 42% reduction in power dissipation (when optimized for area). In a 16×16 design, half of the least significant partial products are truncated for AM1 and AM2, which are thus denoted as TAM1 and TAM2, respectively. Compared with the Wallace multiplier, TAM1 and TAM2 save from 50% to 66% in power, when optimized for area. Compared to existing approximate multipliers, AM1, AM2, TAM1 and TAM2 show significant advantages in accuracy with a high performance. AM2 has a better accuracy compared to AM1 but with a longer delay and higher power consumption. Image processing applications including image sharpening and smoothing are considered to show the quality of the approximate multipliers in error-tolerant applications. By utilizing an appropriate error recovery, the proposed approximate multipliers achieve similar processing accuracy as traditional exact multipliers, but with significant improvements in power.
List of the following materials will be included with the Downloaded Backup:
Low-Power High Precision Floating-Point Divider with Bidimensional Linear Approximation
Base Paper Abstract:
In this paper we propose a novel approximate floating-point divider based on bi-dimensional linear approximation. In our approach, the mantissa quotient is seen as a function of the two input mantissas of the divider. The domain of this two-variable function is partitioned into nx × ny subregions, named tiles, where nx, ny are chosen as powers of two. In each tile the quotient is approximated with a linear combination of the input mantissas. To achieve fine accuracy, an optimization problem is formulated within each tile to determine the optimal coefficients for the linear combination, which minimize the Mean Relative Error Distance (MRED) of the divider. Furthermore, to make hardware implementation more effective, the minimization problem is appropriately modified to search for optimal quantized coefficients. The hardware structure of the divider only requires a small look-up table to store the linear approximation coefficients, and a carry save adder tree. The proposed architecture is highly tunable at design-time over a wide range of accuracy, depending on the number of tiles chosen for the approximation. The obtained results demonstrate error performance and hardware features superior to the state-of-the-art. The proposed dividers define the Pareto front, considering the trade-off between power-delay-product vs. MRED and area-delay-product vs. MRED, for MRED in the range of 4 × 10−3 − 2 × 10−2. Application results for JPEG compression and tone mapping further highlight the strength of our proposal, which exhibits Structural Similarity Index (SSIM) very close to 1 in all cases and Peak Signal-to-Noise Ratio (PSNR) up to 45 db. Index Terms: Floating-point divider, approximate computing, error correction, low-power.
List of the following materials will be included with the Downloaded Backup: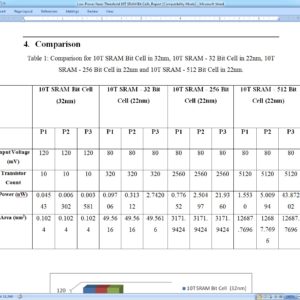
Low-Power Near-Threshold 10T SRAM Bit Cells With Enhanced Data-Independent Read Port Leakage for Array Augmentation in 32-nm CMOS
Abstract:
The conventional six-transistor static random access memory (SRAM) cell allows high density and fast differential sensing but suffers from half-select and read-disturb issues. Although the conventional eight-transistor SRAM cell solves the read-disturb issue, it still suffers from low array efficiency due to deterioration of read bit-line (RBL) swing and Ion/Ioff ratio with increase in the number of cells per column. Previous approaches to solve these issues have been afflicted by low performance, data dependent leakage, large area, and high energy per access. Therefore, in this paper, we present three iterations of SRAM bit cells with nMOS-only based read ports aimed to greatly reduce data dependent read port leakage to enable 1k cells/RBL, improve read performance, and reduce area and power over conventional and 10T cell-based works. We compare the proposed work with other works by recording metrics from the simulation of a 128-kb SRAM constructed with divided-word line-decoding architecture and a 32-bit word size. Apart from large improvements observed over conventional cells, up to 100-mV improvement in read-access performance, up to 19.8% saving in energy per access, and up to 19.5% saving in the area are also observed over other 10T cells, thereby enlarging the design and application gamut for memory designers in low-power sensors and battery-enabled devices.
List of the following materials will be included with the Downloaded Backup:
Low-Power, Low-Energy, Static, Contention-Free, TSPC Dual-Edge Triggered Flip-Flops
Base Paper Abstract:
The dual edge-triggered flip-flop samples the data on both the positive and negative edges of the clock. Hence, it can lead to lower clock relative power consumption as compared to the single-edge triggered flip-flop while maintaining the same data throughput. In this paper, we present two low-power, low-energy dual-edge triggered TSPC flip-flops based on latch-mux type methodology. These two flip-flops, Low-Power at Low Data Activity (LPLD-DET), and Low-Power at High Data Activity (LPHD-DET) are suitable for low-power application. These flip-flops are fully static and contention-free. The post-layout simulation results in TSMC CMOS 65 nm technology suggest that the proposed LPLD-DET is the most power-efficient dual-edge triggered flip-flop for low data activities up to 30%, and LPHD-DET is the most power-efficient dual-edge triggered flip-flop for higher data activities from 45% compared to the other state of-the-art dual-edge triggered TSPC flip-flops.
List of the following materials will be included with the Downloaded Backup:
Low-Voltage Bandgap Reference Circuit in 28nm CMOS
Abstract:
This paper presents a hybrid adjusted temperature compensation circuit for reducing the temperature drift of the bandgap reference. Combining first-order bandgap current, nonlinear compensation current, and temperature curvature compensation current together, a temperature insensitive reference voltage can be obtained in proposed circuit. Designed and verified in UMC 28nm CMOS technology with Cadence IC615, the proposed circuit achieves a post-layout simulation temperature drift of 5.48 ppm/°C in the range of -20°C to 120°C with a supply voltage of 1.05-V.
List of the following materials will be included with the Downloaded Backup: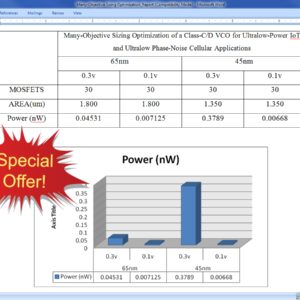
Many-Objective Sizing Optimization of a Class-C/D VCO for Ultralow-Power IoT and Ultralow Phase-Noise Cellular Applications
Abstract:
In this paper, the performance boundaries and corresponding tradeoffs of a complex dual-mode class-C/D voltage controlled oscillator (VCO) are extended using a framework for the automatic sizing of radio frequency integrated circuit blocks, where an all-inclusive test bench formulation enhanced with an additional measurement processing system enables the optimization of “everything at once” toward its true optimal tradeoffs. VCOs embedded in the state-of-the-art multi standard transceivers must comply with extremely high performance and ultralow power requirements for modern cellular and Internet of Things applications. However, the proper analysis of the design tradeoffs is tedious and impractical, as a large amount of conflicting performance figures obtained from multiple modes, test benches, and/or analysis must be considered simultaneously. Here, the dual-mode design and optimization conducted provided 287 design solutions with figures of merit above 192 dBc/Hz, where the power consumption varies from 0.134 to 1.333 mW, the phase noise at 10 MHz from −133.89 to −142.51 dBc/Hz, and the frequency pushing from 2 to 500 MHz/V, on the worst case of the tuning range. These results pushed this circuit design to its performance limits on a 65-nm CMOS technology, reducing 49% of the power consumption of the original design while also showing its potential for ultralow power with more than 93% reduction. In addition, worst case corner criteria were also performed on the top of the worst case tuning range optimization, taking the problem to a human-untrea table LXVI-D performance space.
List of the following materials will be included with the Downloaded Backup:
MInSC: A VLSI Architecture for Myocardial Infarction Stages Classifier for Wearable Healthcare Applications
Base Paper Abstract:
Myocardial Infarction (MI) is a critical heart abnormality causing millions of fatalities worldwide every year. MI progress in three stages based on its severity causing several changes in an Electrocardiogram (ECG) signal. It is very critical to capture these variations, which requires continuous monitoring of the ECG signal of the patient. Therefore, it becomes imperative to develop a low power VLSI architecture to address the prognosis of MI. In this brief, for the first time, an area and power efficient design of a five stage classifier is proposed, which detects the progression of various stages of MI using ECG beats in real time. The proposed architecture has an area and total power utilization of 1.38mm2 and 5.12µW, respectively at SCL 180nm Bulk CMOS technology. The low power and area requirements and multiclass classification capability of the proposed design make it suitable to be used in wearable devices.
List of the following materials will be included with the Downloaded Backup:
Modified Wallace Tree Multiplier using Efficient Square Root Carry Select Adder
A multiplier is one of the key hardware blocks in most digital and high performance systems such as FIR filters, micro processors and digital signal processors etc. A system’s performance is generally determined by the performance of the multiplier because the multiplier is generally the slowest element in the whole system and also it is occupying more area consuming. The Carry Select Adder (CSLA) provides a good compromise between cost and performance in carry propagation adder design. A Square Root Carry Select Adder using RCA is introduced but it offers some speed penalty. However, conventional CSLA is still area-consuming due to the dual ripple carry adder structure. In the proposed work, generally in Wallace multiplier the partial products are reduced as soon as possible and the final carry propagation path carry select adder is used. In this paper, modification is done at gate level to reduce area and power consumption. The Modified Square Root Carry Select-Adder (MCSLA) is designed using Common Boolean Logic and then compared with regular CSLA respective architectures, and this MCSLA is implemented in Wallace Tree Multiplier. This work gives the reduced area compared to normal Wallace tree multiplier. Finally an area efficient Wallace tree multiplier is designed using common Boolean logic based square root carry select adder.
List of the following materials will be included with the Downloaded Backup:
Multiloop Control for Fast Transient DC–DC Converter
Abstract:
A novel ac coupled feedback (ACCF) is proposed to alternatively realize fast transient response while inherently controlling the start-up in-rush current of a dc–dc switching converter. The proposed ACCF is modified from a conventional capacitor multiplier and connected between the outputs of the converter and the transconductance. With this supplemental feedback, the transient response has been significantly improved due to the gain-boosting effect around the compensator’s midband. Moreover, the ACCF circuit assists to manage the ramping speed of the output voltage during power-up, thereby eliminating the bulky soft-start circuit. The new controller is very simple to implement and occupies a tiny footprint on-chip. A buck converter with the proposed scheme has been fabricated using the 0.18-µm standard CMOS process with an active silicon area of 0.573 mm2. Measurement results show that the output voltage rises linearly for a soft-start period of 1.05 ms according to the designed slope. Excellent load transient responses are achieved under different load current steps; the output voltage overshoot/undershoot of 60 mV settles down within 10 µs for a load variation from 50 µA to 1 A in 1 µs. Moreover, the proposed converter maintains both excellent load and line regulations of 0.018 mV/mA and 0.0056 mV/mV, respectively.
List of the following materials will be included with the Downloaded Backup: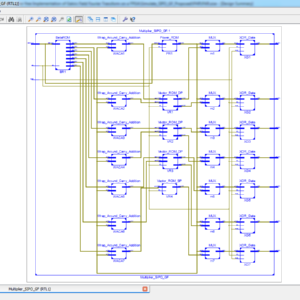
Multiplier-free Implementation of Galois Field Fourier Transform on a FPGA
Abstract:
A novel approach to implementing Galois Field Fourier Transform (GFT) is proposed that completely eliminates the need for any finite field multipliers by transforming the symbols from a vector representation to a power representation. The proposed method is suitable for implementing GFTs of prime and nonprime lengths on modern FPGAs that have a large amount of on-chip distributed embedded memory. For GFT of length 255 that is widely used in many applications, the proposed memory based implementation exhibits 25% improvement in latency, 27% improvement in throughput, and 56% reduction in power consumption compared to a finite field multiplier based implementation.
List of the following materials will be included with the Downloaded Backup:
New Majority Gate Based Parallel BCD Adder Designs for Quantum-dot Cellular Automata
Abstract:
In this paper, we first theoretically re-defined output decimal carry in terms of majority gates and proposed a carry look ahead structure for calculating all the intermediate output carries. We have used this method for designing the multi-digit decimal adders. Theoretically, our best n-digit decimal adder design reduces the delay and area-delay product (ADP) by 50% compared with previous designs. We have implemented our designs using QCA Designer tool. The proposed QCA Designer based 8-digit PBA-BCD adder achieves over 38% less delay compared with the best existing designs.
List of the following materials will be included with the Downloaded Backup:
Novel Block-Formulation and Area-Delay-Efficient Reconfigurable Interpolation Filter Architecture for Multi-Standard SDR Applications
Abstract: The input-matrix and the coefficient-matrix resizes when changes. An analysis of interpolation filter computation for different up-sampling factors is made in this paper to identify redundant computations and removed those by reusing partial results. Reuse of partial results eliminates the necessity of matrix resizing in interpolation filter computation. A novel block-formulation is presented to share the partial results for parallel computation of filter outputs of different up-sampling factors. Using the proposed block formulation, to increase the number of tab to 16 and to get the accuracy and reduce the delay. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2.
List of the following materials will be included with the Downloaded Backup:
Obfuscating DSP Circuits via High Level Transformations
This paper presents a novel approach to design obfuscated circuits for digital signal processing (DSP) applications using high-level transformations, a key-based obfuscating finite-state machine (FSM), and a reconfigurator. The goal is to design DSP circuits that are harder to reverse engineer. High level transformations of iterative data-flow graphs have been exploited for area-speed-power tradeoffs. This is the first attempt to develop a design flow to apply high level transformations that not only meet these tradeoffs but also simultaneously obfuscate the architectures both structurally and functionally. Functional obfuscation is accomplished by requiring use of the correct initialization key, and configure data. Structural obfuscation is also achieved by the proposed methodology via high-level transformations. The proposed architecture of this paper analysis the logic size, area and power consumption using Xilinx 14.2
List of the following materials will be included with the Downloaded Backup:
One-Sided Schmitt-Trigger-Based 9T SRAM Cell for Near-Threshold Operation
Abstract:
This paper presents a one-sided Schmitt-trigger based 9T static random access memory cell with low energy consumption and high read stability, write ability, and hold stability yields in a bit-interleaving structure without write-back scheme. The proposed Schmitt-trigger-based 9T static random access memory cell obtains a high read stability yield by using a one-sided Schmitt-trigger inverter with a single bit-line structure. In addition, the write ability yield is improved by applying selective power gating and a Schmitt-trigger inverter write assist technique that controls the trip voltage of the Schmitt-trigger inverter. The proposed Schmitt-trigger-based 9T static random access memory cell has 0.79, 0.77, and 0.79 times the area, and consumes 0.31, 0.68, and 0.90 times the energy of Chang’s 10T, the Schmitt-trigger-based 10T, and MH’s 9T static random access memory cells, respectively, based on 22-nm Fin FET technology.
List of the following materials will be included with the Downloaded Backup:
Optimized Dual Accumulator based RISC Architecture with Advanced Memory and Peripheral Operations
Proposed Abstract:
This paper presents an optimized Reduced Instruction Set Computer (RISC) architecture that leverages a dual accumulator design to enhance computational efficiency and performance. The architecture is scheduled to support advanced memory management and peripheral operations, addressing the growing need for high-speed data processing in embedded systems. The dual accumulator approach allows for parallel execution of arithmetic operations, reducing the number of instruction cycles and improving overall throughput. The architecture is designed with a focus on optimizing area, delay, and power consumption, making it suitable for resource-constrained environments. The proposed design is implemented using Verilog HDL and synthesized on the Xilinx Vivado platform targeting the Zynq FPGA. The architecture’s performance is verified through extensive simulation in Modelsim, and a comparative analysis is conducted to evaluate the improvements in key parameters such as area utilization, processing delay, and power efficiency. The results demonstrate that the optimized dual accumulator-based RISC architecture significantly outperforms traditional single accumulator designs, making it an ideal solution for modern embedded applications that require both high performance and low power consumption.
List of the following materials will be included with the Downloaded Backup:
Optimizing Ternary Multiplier Design with Fast Ternary Adder
Base Paper Abstract:
Existing ternary multiplier designs are difficult to use in ternary systems. Thus, ternary Wallace tree multipliers that reduce the number of transistors by using 4-input ternary adders are proposed to improve the performance of existing ternary multipliers. A ternary carry-select adder is also proposed to reduce the carry propagation delay, used as a carry-chain adder of the Wallace tree. The proposed multipliers are designed with a custom ternary standard cell library synthesized by multi-threshold complementary metal-oxide-semiconductor (CMOS) with a 28 nm process. Power and delay are verified via HSPICE simulation. The proposed 36 × 36 ternary multiplier shows 79.3% power-delay product improvement over the previous ternary multiplier. The proposed 40 × 40 ternary multiplier shows a power-delay product comparable with that of the 64 × 64 binary multiplier synthesized using Synopsys Design Compiler.
List of the following materials will be included with the Downloaded Backup:
OTA-Based Logarithmic Circuit for Arbitrary Input Signal and Its Application
In this paper, a new design procedure has been proposed for realization of logarithmic function via three phases: 1) differentiation; 2) division; and 3) integration for any arbitrary analog signal. All the basic building blocks, i.e., differentiator, divider, and integrator, are realized by operational transconductance amplifier, a current mode device. Realization of exponential, power law and hyperbolic function as the design examples claims that the proposed synthesis procedure has the potential to design a log-based nonlinear system in a systematic and hierarchical manner. The proposed architecture of this paper area and power consumption analysis using tanner tool.
List of the following materials will be included with the Downloaded Backup:
Parallel Pipelined Architecture and Algorithm for Matrix Transposition Using Registers
Base Paper Abstract:
In this brief, we present a new algorithm and architecture for continuous-flow matrix transposition using registers. The algorithm supports P-parallel matrix transposition. The hardware architecture reaches the theoretical minimums in terms of latency and memory. It is composed of a group of identical cascaded basic swap circuits, whose stages are determined by the corresponding algorithm, and can be controlled via a set of counters. Compared with the state-of-the-art architecture, the proposed architecture supports matrices whose rows and columns are integer multiples of P. Here P can be arbitrary, including but not limited to power-of-two integers. Moreover, our results provide additional insight into continuous-flow non-square matrix transposition.
List of the following materials will be included with the Downloaded Backup:
Power Efficient Approximate Divider Architecture for Error Resilient Applications
Base Paper Abstract:
Approximate computing is an emerging paradigm in error-tolerant applications that leads to power-efficient designs without significant loss in quality. The divider in these applications have complex hardware and more latency among the computational blocks resulting in power consumption. Hence approximating the division module would lead to designs with vastly improved power efficiency. A new approximate subtractor (AxSUB) is proposed in this paper with the intent to reduce the hardware complexity while achieving accuracy within permissible limits. The proposed AxSUB and existing approximate subtractor units are used in the restoring array division (RAD) architecture to prove the efficacy of the AxSUB. Comprehensive error and synthesis analysis are performed on RAD architectures implemented using AxSUB, and existing methods. Our proposed design achieved a 21% decrease in area and a 28% decrease in power consumption compared to the exact design. The proposed and existing RAD architectures is implemented on change detection applications to validate the quality-effort tradeoff.
List of the following materials will be included with the Downloaded Backup:
Power Efficient Tiny Yolo CNN Using Reduced Hardware Resources Based on Booth Multiplier and WALLACE Tree Adders
Base Paper Abstract:
Convolutional Neural Network (CNN) has attained high accuracy and it has been widely employed in image recognition tasks. In recent times, deep learning-based modern applications are evolving and it poses a challenge in research and development of hardware implementation. Therefore, hardware optimization for efficient accelerator design of CNN remains a challenging task. A key component of the accelerator design is a processing element (PE) that implements the convolution operation. To reduce the amount of hardware resources and power consumption, this article provides a new processing element design as an alternate solution for hardware implementation. Modified BOOTH encoding (MBE) multiplier and WALLACE tree-based adders are proposed to replace bulky MAC units and typical adder tree respectively. The proposed CNN accelerator design is tested on Zynq-706 FPGA board which achieves a throughput of 87.03 GOP/s for Tiny-YOLO-v2 architecture. The proposed design allows to reduce hardware costs by 24.5% achieving a power efficiency of 61.64 GOP/s/W that outperforms the previous designs.
List of the following materials will be included with the Downloaded Backup:
Pre Encoded Multipliers Based on Non Redundant Radix 4 Signed Digit Encoding
Abstract: In this paper we are discussed about the new design of pre-encoded multiplier are explored at offline the standard co efficient and storing them in system memory. The co efficient is used in non redundant radix 4 signed digit form. This encoding technique is less complex partial product implementation and more area and power efficient design. Analysis is verifies the proposed system is efficient from the existing system.
List of the following materials will be included with the Downloaded Backup:
Probability-Driven Evaluation of Lower-Part Approximation Adders
Abstract:
Parallel prefix adder topologies suffer from carry chains forming critical paths, limiting the performance and therefore the efficiency. We study approximation methods that offload the lower-part of calculation to an approximate unit and shorten the carry chain. We derive their accuracy models using probability theory. These models can replace Monte Carlo simulations. Furthermore, they can reveal better accuracy trade-offs without going through the RTL design, synthesis, and simulation of each unit and approximation level individually. Thus, they can eliminate the required design and simulation time and effort. After analyzing area-wise comparisons at varying number of approximated bits, we show that choosing a design that outperforms the others probabilistically also outperforms them in terms of accuracy, power, and performance trade-offs.
List of the following materials will be included with the Downloaded Backup:
QPSK Modulator on FPGA
Abstract:
The paper presents the theoretical backgrounds of a QPSK Modulation. The QPSK Modulator is then simulated using Modelsim and Xilinx environment tool for FPGA design as well as implemented on a Spartan 6 LX9 FPGA. The modulator algorithm has been implemented on FPGA using the Verilg HDL language on Xilinx ISE 14.2. The local clock oscillator of the board is 50Mhz which corresponds with a period of 20ns. The frequency of the QPSK carrier is 31,250 kHz and because the QPSK symbol is made of two bits, the output frequency is 62,50kbps. The modulator has been designed and simulated and its performances were evaluated by measurements.
List of the following materials will be included with the Downloaded Backup:
Quaternary Logic Lookup Table in Standard CMOS
Abstract: Interconnections are increasingly the dominant contributor to delay, area and energy consumption in CMOS digital circuits. The proposed implementation overcomes several limitations found in previous quaternary implementations published so far, such as the need for special features in the CMOS process or power-hungry current-mode cells. We have to use the 512bit quaternary Look Up Table for high level of operations in the FPGA. The proposed architecture of this paper will be planned to implemented and also analysis the output current, output voltage, area using Xilinx 14.3.
List of the following materials will be included with the Downloaded Backup:
Quaternary Logic Lookup Table in Standard CMOS
Abstract: Interconnections are increasingly the dominant contributor to delay, area and energy consumption in CMOS digital circuits. The proposed implementation overcomes several limitations found in previous quaternary implementations published so far, such as the need for special features in the CMOS process or power-hungry current-mode cells. We have to use the 512bit quaternary Look Up Table for high level of operations in the FPGA.The proposed architecture of this paper will be planned to implemented and also analysis the output current, output voltage, area using Xilinx 14.3.
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 0.3–0.9-V Voltage-Scalable 14T SRAM and Peripheral Circuit in 28-nm Technology for Space Applications
Abstract:
Conventional radiation-hardened cells of static random access memory (SRAM) are not robust enough in 28 nm technology, due to partial immunity of single-event upset (SEU) effect (Quatrobased cells) or insufficient critical charges in sensitive nodes (conventional stacked cells). The reduction of read noise margin (RNM) at the low supply voltage (VDD) confines these cells from low VDD applications. We propose a novel interleaving stacked-14T (ILS-14T) cell which prevents voltage transient from propagating to other redundancies. The ILS-14T cell can be resilient to both 0–1 and 1–0 upsets by injecting 12 mA in sensitive nodes. The critical charges of the ILS-14T cell are substantially larger than most other hardened cells at VDD from 0.3 to 0.9 V. The RNM of the ILS-14T cell is two times of most Quatro-based cells at 0.3 V VDD and larger than most cells at 0.6 and 0.9 V VDD. The area of occupation is 334% of the conventional 6T cell, which equals other 14T cells. The static–dynamic decoder array with 20%–40% area penalty and 116%–132% delay of rising edge, when compared with the conventional one, reduces the read failure rate by preventing single event transients (SETs) from propagating to unexpected word lines (WLs).
List of the following materials will be included with the Downloaded Backup:
Radiation-Hardened 14T SRAM Bit cell With Speed and Power Optimized for Space Application
Abstract:
In this paper, a novel radiation-hardened 14-transistor SRAM bit cell with speed and power optimized [radiation-hardened with speed and power optimized (RSP)-14T] for space application is proposed. By circuit- and layout-level optimization design in a 65-nm CMOS technology, the 3-D TCAD mixed-mode simulation results show that the novel structure is provided with increased resilience to single-event upset as well as single-event–multiple-node upsets due to the charge sharing among OFF-transistors. Moreover, the HSPICE simulation results show that the write speed and power consumption of the proposed RSP-14T are improved by ∼65% and ∼50%, respectively, compared with those of the radiation hardened design (RHD)-12T memory cell.
List of the following materials will be included with the Downloaded Backup:
RandShift: An Energy-Efficient Fault Tolerant Method in Secure Nonvolatile Main Memory
Abstract:
In this article, we present a simple, yet energy- and area-efficient method for tolerating the stuck-at faults caused by an endurance issue in secure-resistive main memories. In the proposed method, by employing the random characteristics of the encrypted data encoded by the Advanced Encryption Standard (AES) as well as a rotational shift operation, a large number of memory locations with stuck-at faults could be employed for correctly storing the data. Due to the simple hardware implementation of the proposed method, its energy consumption is considerably smaller than that of other recently proposed methods. The technique may be employed along with other error correction methods, including the error correction code (ECC) and the error correction pointer (ECP). To assess the efficacy of the proposed method, it is implemented in a phase-change memory (PCM)- based main memory system and compared with three error tolerating methods. The results reveal that for a stuck-at fault occurrence rate of 10−2 and with the uncorrected bit error rate of 2 × 10−3, the proposed method achieves 82% energy reduction compared to the state-of-the-art method. More generally, using a simulation analysis technique, we show that the fault coverage of the proposed method is similar to that of the state-of-the-art method.
List of the following materials will be included with the Downloaded Backup:
ReAdapt: A Reconfigurable Datapath for Runtime Energy-Quality Scalable Adaptive Filters
Base Paper Abstract:
This paper proposes ReAdapt–a reconfigurable datapath architecture for scaling the energy-quality trade-off of adaptive filtering at runtime. The ReAdapt can dynamically select four adaptive filtering algorithms for gradating complexity levels during runtime by reconfiguring the processing flow in its datapath and by blocking the switching activity (e.g., reducing the CMOS dynamic power) of unused modules with data-gating. The ReAdapt proposal can scale the energy-quality trade-off by choosing the following four different levels of filter algorithms complexity: 1) least mean square (LMS); 2) partial update normalized LMS (PU-NLMS); 3) set-membership normalized LMS (SM-NLMS); 4) normalized LMS (NLMS). The ReAdapt architecture reuses common modules of each adaptive filter, resulting in a compact VLSI hardware implementation. The ReAdapt architecture operation is implemented in a case-study for interference mitigation for electroencephalogram (EEG) signal processing. The hardware synthesis results show an increase of 6.80 times in throughput and at least a reduction of 2.84 times in energy per operation compared with the state-of-the-art adaptive filters. This paper also investigates the benefits of dynamically reconfiguring the four ReAdapt operating modes at runtime for different levels of signal-to-noise ratio (SNR) for the processed signals. We also demonstrate that dynamically reconfiguring the ReAdapt operating modes during runtime results in an optimal energy-quality trade-off which is advantageous over the conventional single static mode.
List of the following materials will be included with the Downloaded Backup:
Reconfigurable Architecture for Real-time Decoding of Canonical Huffman Codes
Base Paper Abstract:
Data compression is an important algorithm which has found its use in modern day algorithms such as Convolutional Neural Networks (CNNs). Reconfigurable platforms (like FPGAs) have strong capabilities to implement time complex tasks like CNNs, however, these algorithms present a big challenge due to high resource demand. Data compression is one of the most utilized techniques to reduce memory utilization in FPGAs. The weights of CNN architecture are usually encoded to store in FPGA. In this paper, we propose design of an efficient decoder based on Canonical Huffman that can be utilized for the efficient decompression of weights in CNN. The proposed design makes use of Hash functions to effectively decode the weights eliminating the need for searching dictionary. The proposed design decodes a single weight in a single clock cycle. Our proposed design has a maximum frequency of 408.97MHz utilizing 1% of system LUTs when tested for Aritix 7 platform.
List of the following materials will be included with the Downloaded Backup:
Reconfigurable Digital Delta-Sigma Modulation Transmitter Architecture for Concurrent Multi-Band Transmission
Abstract:
This paper presents a reconfigurable delta-sigma modulation (DSM) architecture for concurrent multi-band transmission. The reconfigurability in terms of carrier spacing and the number of simultaneous carrier transmission is useful for applications such as carrier aggregation in 5G. This paper uses 4th order reconfigurable multi-band DSM (RMB-DSM) such that the zeros of the noise transfer function can be reconfigured to fall at multiple frequencies, where the carriers are being aggregated. The quantization noise between the transmission bands is a critical issue in the case of multi-band transmission. Therefore, a multi-band additional noise shaping (ANS) function is also introduced, which generates notches around each carrier and reduces the noise level between the multiple pass-bands. The proposed scheme has been validated in simulation, as well as in experiment for aggregating up to four 15 MHz long term evolution (LTE) signals with an overall aggregated bandwidth of 60 MHz. Measurement results show a 10-25% improvement in coding efficiency and 15-35 dB improvement in noise level near the operating frequency band using the proposed multiband augmented noise shaping technique, as compared to the standard DSM. The corresponding improvement of 8% in the overall efficiency is observed by using the proposed multi-band augmented noise shaping technique.
List of the following materials will be included with the Downloaded Backup:
Recurrent Neural Networks With Column-Wise Matrix–Vector Multiplication on FPGAs
Abstract:
This article presents a reconfigurable accelerator for Recurrent Neural networks with fine-grained Column Wise matrix–vector multiplication (RENOWN). We propose a novel latency-hiding architecture for recurrent neural network (RNN) acceleration using column-wise matrix–vector multiplication (MVM) instead of the state-of-the-art row-wise operation. This hardware (HW) architecture can eliminate data dependencies to improve the throughput of RNN inference systems. Besides, we introduce a configurable checkerboard tiling strategy which allows large weight matrices, while incorporating various configurations of element-based parallelism (EP) and vector-based parallelism (VP). These optimizations improve the exploitation of parallelism to increase HW utilization and enhance system throughput. Evaluation results show that our design can achieve over 29.6 tera operations per second (TOPS) which would be among the highest for field-programmable gate array (FPGA)-based RNN designs. Compared to state-of-the-art accelerators on FPGAs, our design achieves 3.7–14.8 times better performance and has the highest HW utilization.
List of the following materials will be included with the Downloaded Backup:
Recursive Approach to the Design of a Parallel Self Timed Adder
Abstract: We are briefly discussed about the 64bit parallel self timed adder based on the recursive formulation. The adder is also based on the asynchronous logic circuit and the transistor is connected in parallel. This adder is chance the path automatically, so the delay is configures automatically. The completion detection unit is given the additional support for practical implementation. The simulation is take place with 130nm CMOS technology for the adder circuit. Finally the power consumption for 64bit adder is 0.29mW.
List of the following materials will be included with the Downloaded Backup:Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Copyright © 2026 Nxfee Innovation.