IEEE Transactions on VLSI 2022
Following Novelty based Research Projects not yet Published in Any Journal
Customization Available for Journal Publications
A Configurable Floating Point Multiple Precision Processing Element for HPC and AI Converged Computing
Abstract:
There is an emerging need to design configurable accelerators for the high-performance computing (HPC) and artificial intelligence (AI) applications in different precisions. Thus, the floating-point (FP) processing element (PE), which is the key basic unit of the accelerators, is necessary to meet multiple-precision requirements with energy-efficient operations. However, the existing structures by using high-precision-split (HPS) and low-precision-combination (LPC) methods result in low utilization rate of the multiplication array and long multi term processing period, respectively. In this article, a configurable FP multiple-precision PE design is proposed with the LPC structure. Half precision, single precision, and double precision are supported. The 100% multiplier utilization rate of the multiplication array for all precisions is achieved with improved speed in the comparison and summation process. The proposed design is realized in a 28-nm process with 1.429-GHz clock frequency. Compared with the existing multiple-precision FP methods, the proposed structure achieves 63% and 88% areasaving performance for FP16 and FP32 operations, respectively. The 4× and 20× maximum throughput rates are obtained when compared with fixed FP32 and FP64 operations. Compared with the previous multiple-precision PEs, the proposed one achieves the best energy-efficiency performance with 975.13 GFLOPS/W.
List of the following materials will be included with the Downloaded Backup:
A High-Speed FPGA-based True Random Number Generator using Metastability with Clock Managers
Base Paper Abstract:
True random number generators (TRNGs) are fundamentals in many important security applications. Though they exploit randomness sources that are typical of the analog domain, digital-based solutions are strongly required especially when they have to be implemented on Field Programmable Gate Array (FPGA)-based digital systems. This paper describes a novel methodology to easily design a TRNG on FPGA devices. It exploits the runtime capability of the Digital Clock Manager (DCM) hardware primitives to tune the phase shift between two clock signals. The presented auto-tuning strategy automatically sets the phase difference of two clock signals in order to force on one or more flip-flops (FFs) to enter the metastability region, used as a randomness source. Moreover, a novel use of the fast carry-chain hardware primitive is proposed to further increase the randomness of the generated bits. Finally, an effective on-chip post-processing scheme that does not reduce the TRNG throughput is described. The proposed TRNG architecture has been implemented on the Xilinx Zynq XC7Z020 System on Chip (SoC). It passed all the National Institute of Standards and Technology (NIST) SP 800-22 statistical tests with a maximum throughput of 300×106 bit per second. The latter is considerably higher than the throughput of other previously published DCMbased TRNGs.
List of the following materials will be included with the Downloaded Backup:
A High-Throughput VLSI Architecture Design of Canonical Huffman Encoder
Abstract:
In this brief, a high-throughput Huffman encoder VLSI architecture based on the Canonical Huffman method is proposed to improve the encoding throughput and decrease the encoding time required by the Huffman code word table construction process. We proposed parallel computing architectures for frequency-statistical sorting and code-size computational sorting. This architecture results in a process of building a tree and assigning symbols that can be completed by scanning the data only once. This solves the problem of the low efficiency of the traditional algorithm, which needs to scan the data twice. Consequently, in addition to the advantages of the high compression ratio inherited from the Canonical Huffman, the proposed architecture has overridden advantages for a high parallelism processing capacity. The experimental results showed that the proposed architecture decreased the encoding time by 26.30% compared to the available Huffman encoder using the standard algorithm when encoding 256 8-bit symbols. Furthermore, the VLSI architecture could further decrease the encoding time when encoding more 8-bit symbols. In particular, when encoding 212,642 8-bit symbols, the proposed VLSI architecture could reduce the encoding time by 87.40%. Thus, compared with the traditional Huffman encoders, this brief achieved the improvement of coding efficiency.
List of the following materials will be included with the Downloaded Backup:
A Novel In-Memory Wallace Tree Multiplier Architecture Using Majority Logic
Abstract:
In-memory computing using emerging technologies such as resistive random-access memory (ReRAM) addresses the ‘von Neumann bottleneck’ and strengthens the present research impetus to overcome the memory wall. While many methods have been recently proposed to implement Boolean logic in memory, the latency of arithmetic circuits (adders and consequently multipliers) implemented as a sequence of such Boolean operations increases greatly with bit-width. Existing in-memory multipliers require O(n2) cycles which is inefficient both in terms of latency and energy. In this work, we tackle this exorbitant latency by adopting Wallace Tree multiplier architecture and optimizing the addition operation in each phase of the Wallace Tree. Majority logic primitive was used for addition since it is better than NAND/NOR/IMPLY primitives. Furthermore, high degree of gate-level parallelism is employed at the array level by executing multiple majority gates in the columns of the array. In this manner, an in-memory multiplier of O(n.log(n)) latency is achieved which outperforms all reported in-memory multipliers. Furthermore, the proposed multiplier can be implemented in a regular transistor-accessed memory array without any major modifications to its peripheral circuitry and is also energy-efficient.
List of the following materials will be included with the Downloaded Backup:
A Reliable Low Standby Power 10T SRAM Cell With Expanded Static Noise Margins
Abstract:
This paper explores a low standby power 10T (LP10T) SRAM cell with high read stability and write-ability (RSNM/WSNM/WM). The proposed LP10T SRAM cell uses a strong cross-coupled structure consisting standard inverter with a stacked transistor and Schmitt-trigger inverter with a double-length pull-up transistor. This along with the read path separated from true internal storage nodes eliminates the read-disturbance. Furthermore, it performs its write operation in pseudo differential form through write bit line and control signal with a write-assist technique. To estimate the proposed LP10T SRAM cell’s performance, it is compared with some state-of-the-art SRAM cells using HSPICE in 16-nm CMOS predictive technology model at 0.7 V supply voltage under harsh manufacturing process, voltage, and temperature variations. The proposed SRAM cell offers 4.65X/1.57X/1.46X improvement in RSNM/WSNM/WM and 4.40X/1.69X narrower spread in RSNM/WM compared to the conventional 6T SRAM cell. Furthermore, it shows 1.26X/1.08X/1.01X higher RSNM/WSNM/WM and 1.71X/1.25X tighter/wider spread in RSNM/WM compared to the best studied SRAM cells. The proposed SRAM cell indicates 74.48%/1.41% higher/lower read/write delay compared to the 6T SRAM cell. Moreover, it exhibits the third-(second-) best read (write) dynamic power, consuming 29.69% (26.87%) lower than the 6T SRAM cell. The leakage power is minimized by the proposed design, which is 37.35% and 12.08% lower than that of the 6T and best studied cells, respectively. Nonetheless, the proposed LP10T SRAM cell occupies 1.313X higher area compared to the 6T SRAM cell.
List of the following materials will be included with the Downloaded Backup:
A Unified Approach for Realization of IIR Filters in Delta Domain
Base Paper Abstract:
In this paper, digital realization of IIR filters is concentrated in discrete delta domain. Whenever, a continuous time filter is discretized at fast sampling rate, corresponding discrete time filter in conventional z-domain realization fails to provide meaningful information. In other way, the delta domain based system provides the continuous time results at fast sampling rate leading to the development of a unified method for filter realization in digital domain. Realization of the digital filter using delta operator is having very good finite word length performance under high sampling rate. Three different types of IIR filters are considered for the digital realization in delta domain. The transposed delta direct form II (DDFT-II) structure is used to realize the filters, as it is the most suitable structure for digital filter realization. Butterworth, Chebyshev -2 and Elliptic filters are considered as example and MATLAB Simulink is used to realize the digital filter in delta domain. The frequency
List of the following materials will be included with the Downloaded Backup:
Advanced Encryption Standard Algorithm with Optimal S-box and Automated Key Generation
Base Paper Abstract:
Advanced Encryption Standard (AES) algorithm plays an important role in a data security application. In general S-box module in AES will give maximum confusion and diffusion measures during AES encryption and cause significant path delay overhead. In most cases, either LUTs or embedded memories are used for S- box computations which are vulnerable to attacks that pose a serious risk to real-world applications. In this paper, implementation of the composite field arithmetic-based Sub-bytes and inverse Sub-bytes operations in AES is done. The proposed work includes an efficient multiple round AES cryptosystem with higher-order transformation and composite field s-box formulation with some possible inner stage pipelining schemes which can be used for throughput rate enhancement along with path delay optimization. Finally, input biometric-driven key generation schemes are used for formulating the cipher key dynamically, which provides a higher degree of security for the computing devices.
List of the following materials will be included with the Downloaded Backup:
Algorithm Level Error Detection in Low Voltage Systolic Array
Base Paper Abstract:
In this brief an approach is proposed to achieve energy savings from reduced voltage operation. The solution detects timing-errors by integrating Algorithm Based Fault Tolerance (ABFT) into a digital architecture. The approach has been studied with a systolic array matrix multiplier operating at reduced voltages, detecting errors on-the-fly to avoid energy demanding memory round-trips. The analysis of the solution has been done using analog-digital co-simulation to extract the transient behavior under different voltages and clock frequencies. HSPICE simulations using 90nm CMOS transistor models, and experiments by reducing operation voltage of an FPGA device were carried out. HSPICE simulations, showed possibility of 10x increase in energy-efficiency by approaching near-threshold region.
List of the following materials will be included with the Downloaded Backup: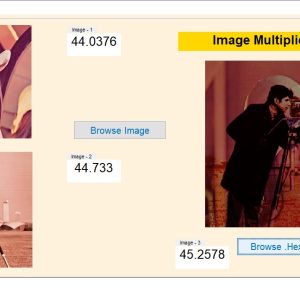
Area and Power Efficient Truncated Booth Multipliers Using Approximate Carry-Based Error Compensation
Base Paper Abstract:
Approximate computing is a promising technique to elevate the performance of digital circuits at the cost of reduced accuracy in numerous error-resilient applications. Multipliers play a key role in many of these applications. In this brief, we propose a truncation based Booth multiplier with a compensation circuit generated by selective modifications in k-map to circumvent the carry appearing from the truncated part. By judicious mapping, hardware pruning and output error reduction is achieved simultaneously. In the quest of power and accuracy trade-off, Truncated and Approximate Carry based Booth Multipliers (TACBM) are proposed with a range of designs based on truncation factor w. When compared with the state-of-the-art multipliers, TACBM outperforms in terms of accuracy and Area Power savings. TACBM (w = 10) provides with 0.02% MRED and 23% reduction in Area-Power product compared to exact Booth multiplier. The multipliers are evaluated using image blending and Multilayer perceptron (MLP) neural network and a high value of accuracy (95.63%) for MLP is achieved.
List of the following materials will be included with the Downloaded Backup:
Design and Analysis of a Majority Logic Based Imprecise 6-2 Compressor for Approximate Multipliers
Base Paper Abstract:
Approximate computing is an emerging paradigm for trading off computing accuracy to reduce energy consumption and design complexity in a variety of applications, for which exact computation is not a critical requirement. Different from conventional designs using AND-OR and XOR gates, the majority gate is widely used in many emerging nanotechnologies. An ultra-efficient 6-2 compressor is proposed in this paper. It is composed of two majority gates that lead to low energy consumption and high hardware efficiency. The proposed compressor is utilized in the approximate partial product reduction of a modified 8×8 Dadda multiplier with a truncated structure. Experimental results show that this multiplier realizes a significant reduction in hardware cost, especially in terms of power and area, on average by up to 40% and 31% respectively, compared to exact and state-of-the-art designs. The application of image multiplication is also presented to assess the practicability of the multiplier. The results show that the proposed multiplier results in images with higher quality in peak signal to noise ratio (PSNR) and mean structural similarity index metric (MSSIM) compared to other designs.
List of the following materials will be included with the Downloaded Backup:
FPGA Implementation of Single Precision Floating Point Multiplier using High Speed Parallel Prefix Adder based Wallace Tree Multiplier
Base Paper Abstract:
In this paper present, an efficient implementation of single precision method of floating point multiplier target for Xilinx Vertex 5 FPGA using Verilog HDL. The floating point implementation will cover up with 23-bit exponent, 8-bit mantissa, and 1 sign bit. This proposed architecture implement with high speed parallel prefix adder based Wallace Tree Multiplier. a Wallace tree multiplication will provide effective terms of low logic sizes and more speed of operations. In a recent arithmetic applications based circuit design will have more demand with high speed and low area, in this manner the proposed approach of this work will improve the speed of Wallace tree multiplier using 4:2 compressor method without degrading its area parameter. Thus, the proposed method will integrate more efficient and more reliable Kogge stone parallel prefix, Brent kung parallel prefix, Sklansky parallel prefix addition operation in the Wallace tree multiplication on final addition stage at 16-bit data width. Finally, done this floating point multiplier architecture with Wallace tree architecture included normalized rounding method and to reduce area, delay and power. The error difference will have analyzed using Modelsim Software, and analyses optimized logic size's, delay and power consumptions.
List of the following materials will be included with the Downloaded Backup:
Hardware Architecture for Adaptive Edge Directed Interpolation Algorithm
Base Paper Abstract:
Demosaicking refers to the reconstruction of full color image by the incomplete color samples produced by the single-chip image sensor. So there is a need of interpolation to obtain the missing color pixels. In this work a hardware architecture has been proposed for the adaptive edge-directed interpolation algorithm which uses an edge estimator for the interpolation. The proposed hardware architecture is implemented in Verilog HDL (Hardware Description Language) and synthesized using Cadence Genus compiler with 90nm technology in typical mode. For the proposed architecture, the power dissipation is found to be 26 mW, delay is 7.2 ns and requires 2.3 mm2 area. The demosaicked images obtained using the proposed architecture is observed to have better image quality in terms of peak signal-to-noise ratio and structural similarity while comparing with existing architectures.
List of the following materials will be included with the Downloaded Backup: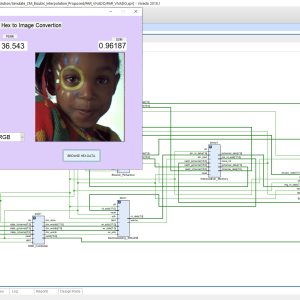
Image Demosaicking using Super Resolution Techniques
Base Paper Abstract:
Limitations do exist on capturing the full color information in a scene, apart from the resolution of captured images. Therefore, mosaic images are the preferred format in digital cameras, where incomplete set of color information is acquired. In this paper, a super resolution demosaicking (SRD) approach is proposed to reconstruct an enhanced-resolution full-color image from the observed samples, robustly and without the need for a training process. The acquisition model assumes degraded observations using known blur and noise. The reconstruction approach iteratively estimates the unknown registration parameters and the demosaicking image simultaneously. Qualitative and quantitative experiments performed on synthetic observations reveal high performance images.
List of the following materials will be included with the Downloaded Backup: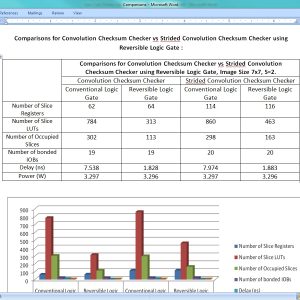
Low Cost Online Convolution Checksum Checker
Abstract:
Managing random hardware faults requires the faults to be detected online, thus simplifying recovery. Algorithm-based fault tolerance has been proposed as a low-cost mechanism to check online the result of computations against random hardware failures. In this case, the checksum of the actual result is checked against a predicted checksum computed in parallel by a hardware checker. In this work, we target the design of such checkers for convolution engines that are currently the most critical building block in image processing and computer vision applications. The proposed convolution checksum checker, named ConvGuard, utilizes a newly introduced invariance condition of convolution to predict implicitly the output checksum using only the pixels at the border of the input image. In this way, ConvGuard reduces the power required for accumulating the input pixels without requiring large buffers to hold intermediate checksum results. The design of ConvGuard is generic and can be configured for different output sizes and strides. The experimental results show that ConvGuard utilizes only a small percentage of the area/power of an efficient convolution engine while being significantly smaller and more power efficient than a state-of-the-art checksum checker for various practical cases.
List of the following materials will be included with the Downloaded Backup: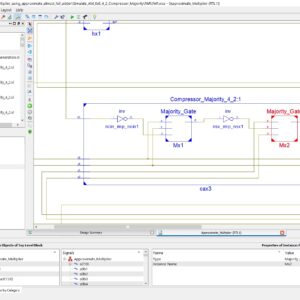
Low power Dadda multiplier using approximate almost full adder and Majority logic based adder compressors
Base Paper Abstract:
An Approximate computing is widely used to have energy-efficient system design in Very Large-Scale Integration (VLSI). This approach is best suited for signal processing and multimedia applications where low power consumption is the main concern. Faster and significant results can be obtained from an approximate computing at the cost of reduced accuracy. In this work, we proposed a very novel design approaches based on various monolithic 4:2 compressors. Proposed approach is applied to have reduced stages in the partial product multiplication. Proposed Monolithic compressor had outperformed over various 4:2 compressors. Our proposed method is based on majority logic based with the use of Dadda multiplication. A new-partial product reduction format is implemented by this multiplier, which reduces the maximum output delay. This method of approach significantly reduces the utilization of number of MOSFETs compared to other multiplier such as Wallace Tree Multipliers. Simulation results are compared with conventional Dadda multiplier and ML based 4:2 compressors. Proposed approximate computing based almost full adder based majority logic based Dadda multiplier achieves reduction of 60.93% in area utilization 72.48% reduction in dynamic power reduction while processing time is also reduced by 72.98%. Dadda multiplication outperforms the other compressors.
List of the following materials will be included with the Downloaded Backup: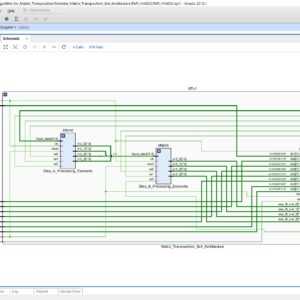
Parallel Pipelined Architecture and Algorithm for Matrix Transposition Using Registers
Base Paper Abstract:
In this brief, we present a new algorithm and architecture for continuous-flow matrix transposition using registers. The algorithm supports P-parallel matrix transposition. The hardware architecture reaches the theoretical minimums in terms of latency and memory. It is composed of a group of identical cascaded basic swap circuits, whose stages are determined by the corresponding algorithm, and can be controlled via a set of counters. Compared with the state-of-the-art architecture, the proposed architecture supports matrices whose rows and columns are integer multiples of P. Here P can be arbitrary, including but not limited to power-of-two integers. Moreover, our results provide additional insight into continuous-flow non-square matrix transposition.
List of the following materials will be included with the Downloaded Backup: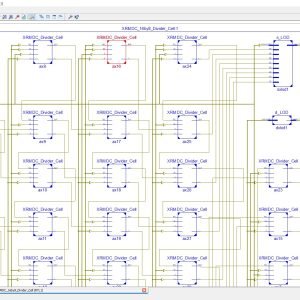
Power Efficient Approximate Divider Architecture for Error Resilient Applications
Base Paper Abstract:
Approximate computing is an emerging paradigm in error-tolerant applications that leads to power-efficient designs without significant loss in quality. The divider in these applications have complex hardware and more latency among the computational blocks resulting in power consumption. Hence approximating the division module would lead to designs with vastly improved power efficiency. A new approximate subtractor (AxSUB) is proposed in this paper with the intent to reduce the hardware complexity while achieving accuracy within permissible limits. The proposed AxSUB and existing approximate subtractor units are used in the restoring array division (RAD) architecture to prove the efficacy of the AxSUB. Comprehensive error and synthesis analysis are performed on RAD architectures implemented using AxSUB, and existing methods. Our proposed design achieved a 21% decrease in area and a 28% decrease in power consumption compared to the exact design. The proposed and existing RAD architectures is implemented on change detection applications to validate the quality-effort tradeoff.
List of the following materials will be included with the Downloaded Backup:
Probability-Driven Evaluation of Lower-Part Approximation Adders
Abstract:
Parallel prefix adder topologies suffer from carry chains forming critical paths, limiting the performance and therefore the efficiency. We study approximation methods that offload the lower-part of calculation to an approximate unit and shorten the carry chain. We derive their accuracy models using probability theory. These models can replace Monte Carlo simulations. Furthermore, they can reveal better accuracy trade-offs without going through the RTL design, synthesis, and simulation of each unit and approximation level individually. Thus, they can eliminate the required design and simulation time and effort. After analyzing area-wise comparisons at varying number of approximated bits, we show that choosing a design that outperforms the others probabilistically also outperforms them in terms of accuracy, power, and performance trade-offs.
List of the following materials will be included with the Downloaded Backup:
Reconfigurable Architecture for Real-time Decoding of Canonical Huffman Codes
Base Paper Abstract:
Data compression is an important algorithm which has found its use in modern day algorithms such as Convolutional Neural Networks (CNNs). Reconfigurable platforms (like FPGAs) have strong capabilities to implement time complex tasks like CNNs, however, these algorithms present a big challenge due to high resource demand. Data compression is one of the most utilized techniques to reduce memory utilization in FPGAs. The weights of CNN architecture are usually encoded to store in FPGA. In this paper, we propose design of an efficient decoder based on Canonical Huffman that can be utilized for the efficient decompression of weights in CNN. The proposed design makes use of Hash functions to effectively decode the weights eliminating the need for searching dictionary. The proposed design decodes a single weight in a single clock cycle. Our proposed design has a maximum frequency of 408.97MHz utilizing 1% of system LUTs when tested for Aritix 7 platform.
List of the following materials will be included with the Downloaded Backup:
Recurrent Neural Networks With Column-Wise Matrix–Vector Multiplication on FPGAs
Abstract:
This article presents a reconfigurable accelerator for Recurrent Neural networks with fine-grained Column Wise matrix–vector multiplication (RENOWN). We propose a novel latency-hiding architecture for recurrent neural network (RNN) acceleration using column-wise matrix–vector multiplication (MVM) instead of the state-of-the-art row-wise operation. This hardware (HW) architecture can eliminate data dependencies to improve the throughput of RNN inference systems. Besides, we introduce a configurable checkerboard tiling strategy which allows large weight matrices, while incorporating various configurations of element-based parallelism (EP) and vector-based parallelism (VP). These optimizations improve the exploitation of parallelism to increase HW utilization and enhance system throughput. Evaluation results show that our design can achieve over 29.6 tera operations per second (TOPS) which would be among the highest for field-programmable gate array (FPGA)-based RNN designs. Compared to state-of-the-art accelerators on FPGAs, our design achieves 3.7–14.8 times better performance and has the highest HW utilization.
List of the following materials will be included with the Downloaded Backup:
Soft-Error-Aware Read-Stability-Enhanced Low-Power 12T SRAM With Multi-Node Upset Recoverability for Aerospace Applications
Abstract:
With the advancement of technology, the size of transistors and the distance between them are reducing rapidly. Therefore, the critical charge of sensitive nodes is reducing, making SRAM cells, used for aerospace applications, more vulnerable to soft-error. If a radiation particle strikes a sensitive node of the standard 6T SRAM cell, the stored data in the cell are flipped, causing a single-event upset (SEU). Therefore, in this paper, a Soft-Error-Aware Read-Stability-Enhanced Low Power 12T (SARP12T) SRAM cell is proposed to mitigate SEUs. To analyze the relative performance of SARP12T, it is compared with other recently published soft-error-aware SRAM cells, QUCCE12T, QUATRO12T, RHD12T, RHPD12T and RSP14T. All the sensitive nodes of SARP12T can regain their data even if the node values are flipped due to a radiation strike. Furthermore, SARP12T can recover from the effect of single event multi-node upsets (SEMNUs) induced at its storage node pair. Along with these advantages, the proposed cell exhibits the highest read stability, as the ‘0’-storing storage node, which is directly accessed by the bit line during read operation, can recover from any upset. Furthermore, SARP12T consumes the least hold power. SARP12T also exhibits higher write ability and shorter write delay than most of the comparison cells. All these improvements in the proposed cell are obtained by exhibiting only a slightly longer read delay and consuming slightly higher read and write energy.
List of the following materials will be included with the Downloaded Backup:
Two-Stage OTA With All Subthreshold MOSFETs and Optimum GBW to DC-Current Ratio
Base Paper Abstract:
An approach for the design of two-stage class AB OTAs with sub-1µA current consumption is proposed and demonstrated. The approach employs MOS transistors operating in subthreshold and allows maximum gain-bandwidth product (GBW) to be achieved for a given DC current budget, by setting optimum distribution of DC currents in the two amplifier stages. Following this strategy, a class AB OTA was designed in a standard 0.5-µm CMOS technology supplied from 1.6-V and experimentally tested. Measured GBW was 307 kHz with 980-nA DC current consumption while driving an output capacitance of 40 pF with an average slew rate of 96 V/ms.
List of the following materials will be included with the Downloaded Backup:
Variable-Precision Approximate Floating-Point Multiplier for Efficient Deep Learning Computation
Base Paper Abstract:
In this brief, a variable-precision approximate floating-point multiplier is proposed for energy efficient deep learning computation. The proposed architecture supports approximate multiplication with BFloat16 format. As the input and output activations of deep learning models usually follow normal distribution, inspired by the posit format, for numbers with different values, different precisions can be applied to represent them. In the proposed architecture, posit encoding is used to change the level of approximation, and the precision of the computation is controlled by the value of product exponent. For large exponent, smaller precision multiplication is applied to mantissa and for small exponent, higher precision computation is applied. Truncation is used as approximate method in the proposed design while the number of bit positions to be truncated is controlled by the values of the product exponent. The proposed design can achieve 19% area reduction and 42% power reduction compared to the normal BFloat16 multiplier. When applying the proposed multiplier in deep learning computation, almost the same accuracy as that of normal BFloat16 multiplier can be achieved.
List of the following materials will be included with the Downloaded Backup:IEEE Transactions on VLSI, VLSI IEEE Project, VLSI Low Power Project, VLSI High Speed Project, VLSI Area Efficient Project, Low Cost VLSI Projects, High Speed VLSI Design projects ( CDMA, RTOS, DSP, RF, IF, etc), Low Power VLSI Design projects, Area Efficient VLSI Design projects , Audio processing VLSI Design projects, Signal Processing VLSI Design projects, Image Processing VLSI Design projects, Backend VLSI Design projects ( CMOS, TFET, BisFET, FeFET, etc), Timing & Delay Reduction VLSI Projects, Internet of Things VLSI Projects, Testing, Reliability and Fault Tolerance VLSI Projects, VLSI Applications ( Communicational, Video, Security, Sensor Networks, etc), SOC VLSI Projects, Network on Chip VLSI Projects, Wireless Communication VLSI Projects, VLSI Verifications Projects ( UVM, OVM, VVM, System Verilog.
Provide Wordlwide Online Support
We can provide Online Support Wordlwide, with proper execution, explanation and additionally provide explanation video file for execution and explanations.
24/7 Support Center
NXFEE, will Provide on 24x7 Online Support, You can call or text at +91 9789443203, or email us nxfee.innovation@gmail.com
Terms & Conditions:
Customer are advice to watch the project video file output, and before the payment to test the requirement, correction will be applicable.
After payment, if any correction in the Project is accepted, but requirement changes is applicable with updated charges based upon the requirement.
After payment the student having doubts, correction, software error, hardware errors, coding doubts are accepted.
Online support will not be given more than 3 times.
On first time explanation we can provide completely with video file support, other 2 we can provide doubt clarifications only.
If any Issue on Software license / System Error we can support and rectify that within end of day.
Extra Charges For duplicate bill copy. Bill must be paid in full, No part payment will be accepted.
After payment, to must send the payment receipt to our email id.
Powered by NXFEE INNOVATION, Pondicherry.
Call us today at : +91 9789443203 or Email us at nxfee.innovation@gmail.com
NXFEE Development & Services

Product Categories
- 2014 (11)
- 2015 (39)
- 2016 (30)
- 2017 (16)
- 2018 (17)
- 2019 (42)
- 2020 (29)
- 2021 (17)
- 2022 (23)
- Accessories (54)
- Area Efficient (119)
- High speed VLSI Design (59)
- IEEE (15)
- Image Processing (40)
- Low power VLSI Design (102)
- NOC VLSI Design (2)
- VLSI (260)
- VLSI 2023 (21)
- VLSI 2024 (18)
- VLSI 2025 (33)
- VLSI 2026 (9)
- VLSI Application / Interface and Mini Projects (33)
- VLSI_2023 (15)
Filter by price
Product Status
Sort by producents

Copyright © 2026 Nxfee Innovation.