HDFC BANK ACCOUNT:
- NXFEE INNOVATION,
HDFC BANK, MAIN BRANCH, PONDICHERRY-605004.
INDIA,
ACC NO. 50200090465140,
IFSC CODE: HDFC0000407.

₹20,000.00 Original price was: ₹20,000.00.₹10,000.00Current price is: ₹10,000.00.
Source : Verilog HDL
Base Paper Abstract:
Cyclic Redundancy Check (CRC) is widely used for transmission error detection in various communication interfaces. As the transmission rate increases, accelerating CRC with lower resource consumption for high-speed interfaces becomes significant. This paper analyzes and implements a typical CRC algorithm (Stride-x) and designs a padding-zero strategy to support the input data length with multiples of byte. Besides, experiments are conducted to validate the proposed algorithm on Xilinx FPGA platforms. When stride is 1, the proposed algorithm outperforms a typical parallel CRC algorithm in throughput and resource consumption with various input bus widths (32/128/256 bits).
List of the following materials will be included with the Downloaded Backup:
Proposed Title:
Improvement of this project :
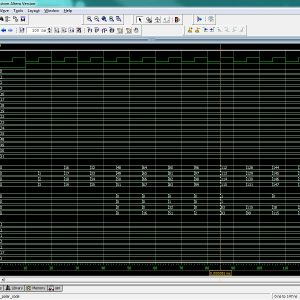
Software Implementation:
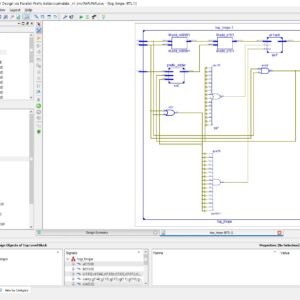
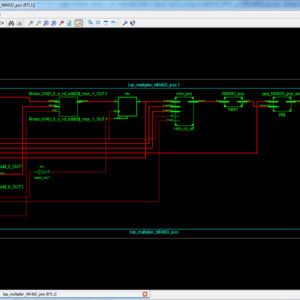
Proposed System:
Cyclic Redundancy Check (CRC) is a widely used error-detecting code that ensures the integrity of data in communication systems and storage devices. This paper presents a novel implementation of an 8-input Look-Up Table (LUT) architecture for efficient CRC computation with stride lengths varying from 1 to 32. By leveraging the LUT-based approach, the proposed design aims to optimize both speed and resource utilization in FPGA. The traditional CRC computation methods often involve sequential bitwise processing, which can be time-consuming and resource-intensive. In contrast, the proposed 8-input LUT architecture allows for parallel processing of multiple bytes, significantly accelerating the CRC computation. This paper explores the design and implementation of the LUT architecture, detailing the generation of precomputed CRC values for different polynomials, including CRC-32, CRC-64, CRC-128, CRC-256, and CRC-512. For each stride length—Stride 1 (8 bits), Stride 2 (16 bits), Stride 4 (32 bits), Stride 8 (64 bits), Stride 16 (128 bits), and Stride 32 (256 bits)—the architecture efficiently maps input data to corresponding CRC values using the precomputed LUTs. The performance of the 8-input LUT architecture is evaluated in terms of logic utilization, computation speed, and power consumption. Experimental results demonstrate that the proposed design achieves significant improvements in processing speed and resource efficiency compared to traditional CRC computation methods. The scalability of the architecture with different stride lengths offers flexibility in balancing throughput and hardware complexity, making it an ideal solution for high-speed data transmission and storage applications. This research contributes to the field of digital design by providing a robust and scalable approach to CRC computation, paving the way for more efficient error-detection mechanisms in modern communication systems.
” Thanks for Visit this project Pages – Buy It Soon “
Payment Method :
HDFC BANK ACCOUNT:
₹18,000.00 Original price was: ₹18,000.00.₹10,000.00Current price is: ₹10,000.00.


₹25,000.00 Original price was: ₹25,000.00.₹10,000.00Current price is: ₹10,000.00.
Copyright © 2026 Nxfee Innovation.
A High Speed CRC-32 Implementa...
₹20,000.00 Original price was: ₹20,000.00.₹10,000.00Current price is: ₹10,000.00.